


Время — деньги. Час простоя ИТ-инфраструктуры для бизнеса исчисляется в рублях. Чем крупнее бизнес, тем больше стоимость часа простоя.
Технические сбои неизбежны. Отказ жесткого диска, ошибка в конфигурации сети, успешная кибератака или случайно выполненная команды DROP DATABASE — вопрос не в том, случится ли катастрофа, а в том, когда это произойдет. Одно дело — потерять данные, и совсем другое — не знать, как их вернуть.
Индустрия давно выработала стандарты противодействия таким ситуациям, и ключевым звеном здесь является Disaster Recovery Plan (DRP). Это не просто набор скриптов резервного копирования, а комплексная, задокументированная стратегия, базирующаяся на критически важных метриках RTO (допустимое время простоя) и RPO (допустимая потеря данных).
Что такое DRP?
Любой DRP базируется на двух фундаментальных показателях, которые должны быть определены на этапе бизнес-анализа. Эти метрики — не просто цифры, а технические требования к архитектуре резервирования и скорости реагирования.
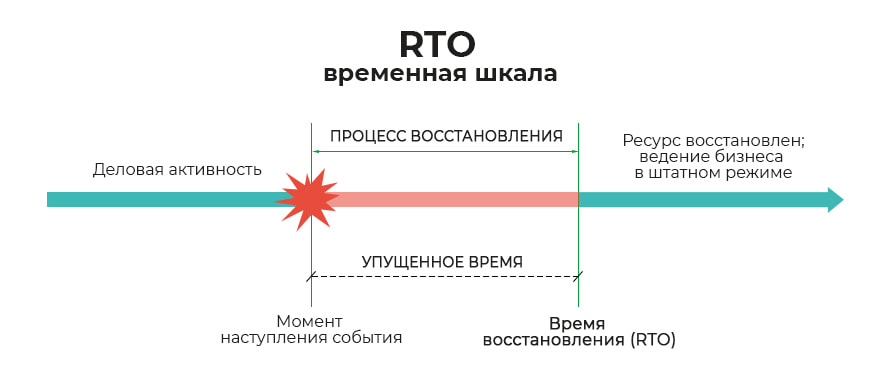
RTO (Recovery Time Objective) — целевое время восстановления. Период, в течение которого система может оставаться недоступной в случае аварии или сбоя. Это минимальное время, за которое должна восстановиться система после инцидента любого уровня.
Для системного администратора RTO — это жёсткий дедлайн. Он диктует выбор технологий и архитектуры для восстановления данных.
Если RTO измеряется минутами, тогда это требование подразумевает наличие "горячего" резерва (активного/пассивного кластера или реплицированной инфраструктуры в другом ЦОДе). Процессы восстановления должны быть максимально автоматизированы (оркестрация).
Если RTO измеряется часами или днями, то допустимо использование "холодного" резерва, когда серверы не включены постоянно, а разворачиваются из шаблонов или с использованием физических носителей. Восстановление может быть частично или полностью ручным.
RTO жестко привязан к скорости чтения данных с лент и дисков, скорости поднятия виртуальных машин из резервных копий или времени переключения сервиса на резервную площадку.
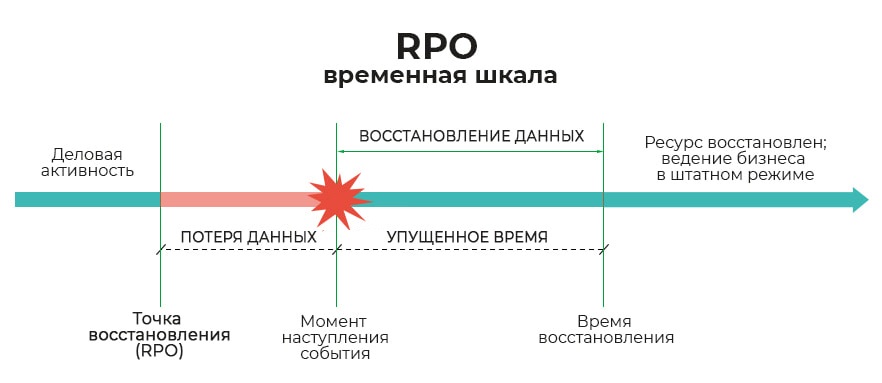
RPO (Recovery Point Objective) — целевая точка восстановления. Это максимально допустимый период времени, в течение которого данные могут быть утеряны в результате сбоя, аварии или кибератаки.
RPO — это требование к частоте создания резервных копий и способу репликации данных.
Нулевое значение (RPO = 0) означает "нулевую потерю данных". Технически реализуется только через синхронную репликацию на удаленную площадку. Каждая транзакция записывается одновременно в двух местах. Важно понимать, что это требование критично к задержкам каналов связи.
RPO = N часов/минут достигается асинхронной репликацией или периодическим созданием резервных копий. Чем меньше RPO, тем чаще происходит захват изменений и тем больше требований к пропускной способности каналов в штатном режиме.
RTO и RPO неразрывно связаны и часто конфликтуют. Например, требование RPO=0 (синхронная репликация) может замедлить производительность приложения из-за задержек сети, что повлияет на бизнес-процессы еще ДО катастрофы. Задача ИТ-архитектора — найти баланс.
Пример формулировки в DRP:
Для системы CRM установлены следующие целевые метрики: RTO = 4 часа, RPO = 1 час. Это означает, что после сбоя инженеры обязаны ввести систему в строй не позднее чем через 4 часа, при этом максимальная потеря данных не должна превышать последний час перед сбоем. Достигается ежечасным созданием снапшотов дисков и наличием предварительно развернутой резервной инфраструктуры.
Таким образом, RTO и RPO — это не просто абстрактные определения, а конкретные входные данные для проектирования систем резервирования, восстановления и выбора инструментов аварийного восстановления.
Типы стратегий восстановления
Выбор стратегии восстановления — это всегда компромисс между скоростью возвращения системы в строй и стоимостью владения инфраструктурой. Принято выделять три классические модели резервирования, которые различаются степенью готовности резервных мощностей к немедленной эксплуатации.
Холодное резервирование
Резервная площадка существует лишь номинально. Там может быть установлено минимально необходимое оборудование (стойки, коммутация, кондиционирование) или даже просто арендовано место в ЦОДе. Сами серверы либо выключены, либо отсутствуют физически и доставляются по мере необходимости. Актуальные данные отсутствуют — есть только резервные копии на лентах или в удаленном объектном хранилище.
Процесс активации холодного резерва:
- Закупка/доставка оборудования, если оно не установлено
- Монтаж и коммутация серверов
- Установка ОС и ПО (или разворачивание из «золотых» образов)
- Восстановление данных из резервных копий (последний этап)
Временные показатели:
- RTO: от 24 часов до нескольких суток (иногда недель, если требуется закупка оборудования)
- RPO: определяется расписанием бэкапов (обычно последняя полная копия + инкременты)
Применимо для систем с низкими требованиями к доступности (архивы, тестовые среды, dev-стенды). Или в бюджетных сценариях, где допустимы длительные простои. Также для защиты от фатальных событий (пожар в основном ЦОД), когда важнее сохранить данные, а не доступность.
Плюсы: минимальная стоимость содержания резервной площадки. Минусы: высокий риск не уложиться в бизнес-требования по времени простоя; человеческий фактор (в стрессовой ситуации развертывание вручную чревато ошибками).
Теплое резервирование
На резервной площадке постоянно развернута и включена минимально необходимая конфигурация инфраструктуры. Как правило, это несколько серверов (физических или виртуальных) с предустановленным ПО, но с пониженной производительностью или без полной нагрузки. Данные синхронизируются с основной площадкой с некоторой задержкой (асинхронно) либо периодически обновляются из резервных копий.
Процесс активации тёплого резерва:
- Подъем критически важных сервисов на уже готовых серверах
- Подтягивание актуальных данных (докачка последних изменений)
- Масштабирование мощностей (добавление вычислительных ресурсов, если требуется полная производительность)
- Переключение трафика (например, через смену DNS или правил на балансировщике)
Временные показатели:
- RTO: от 2 до 24 часов (в зависимости от степени автоматизации и объема данных для финальной синхронизации)
- RPO: часы или десятки минут (определяется частотой асинхронной репликации или бэкапов)
Применимо для системы среднего уровня критичности (внутренние порталы, корпоративная почта без жестких SLA). Или в сценариях, где простой в несколько часов приемлем, но потеря данных за сутки — нет. Также компромиссный вариант при ограниченном бюджете.
Плюсы: существенно быстрее холодного резерва при умеренных затратах. Минусы: требует постоянного мониторинга и синхронизации конфигураций; сложность обеспечения актуальности ПО на обеих площадках.
Горячее резервирование
Полное дублирование инфраструктуры в реальном времени. Резервная площадка является точной копией основной: те же вычислительные мощности, сетевая связность, актуальное состояние данных. Используется синхронная или близкая к реальному времени асинхронная репликация данных. Системы на резервной площадке либо находятся в режиме "активный-активный", либо в режиме "активный-пассивный".
Процесс активации горячего резерва:
- Обнаружение сбоя на основном узле (мониторинг).
- Автоматическое или ручное переключение трафика на резервную площадку.
- Продолжение работы с минимальной паузой (обычно не заметной для пользователя).
Временные показатели:
- RTO: секунды или минуты (ограничивается временем детекции сбоя и срабатывания механизмов failover).
- RPO: от нуля (синхронная репликация) до нескольких секунд/минут (асинхронная).
Применимо для критически важные системы (онлайн-платежи, биржевые платформы, экстренные службы, CRM с высокими требованиями к uptime). В сценариях, где минутный простой означает прямые финансовые потери или репутационный ущерб. Применяется в компаниях с выделенным бюджетом на отказоустойчивость.
Плюсы: максимальная непрерывность бизнеса; автоматизация снижает влияние человеческого фактора. Минусы: высокая стоимость (оборудование ×2, каналы связи, лицензирование); сложность реализации синхронной репликации на больших расстояниях.
Этапы создания DRP
Разработка DRP — это не разовое мероприятие по написанию документа, а полноценный инженерный процесс.
Этапы:
- Бизнес-анализ (BIA — Business Impact Analysis)
- Инвентаризация ресурсов (Discovery & Mapping)
- Определение RTO и RPO (Утверждение целевых метрик)
- Выбор команды реагирования (Roles & Responsibilities)
- Документирование процедур (Runbooks & Playbooks)
- Коммуникационный план (Communication Matrix)
Бизнес-анализ
Прежде чем писать технические инструкции, необходимо понять, что именно бизнес считает критичным. Ошибка на этом этапе приводит к ситуации, когда ИТ восстанавливает системы в порядке, который не соответствует реальным потребностям компании.
Что делаем?
- Проводим интервью с владельцами бизнес-процессов (или изучаем регламенты)
- Идентифицируем критичные бизнес-функции (продажи, производство, логистика, отчетность)
- Определяем, какие ИТ-сервисы обеспечивают эти функции
- Оцениваем финансовые и репутационные потери от простоя каждого сервиса (по часам / по дням)
В результате получаем документ: матрицу приоритетов ИТ-сервисов с указанием:
- Критичности (High/Medium/Low)
- Зависимостей (сервис А не работает без сервиса Б)
- Сезонности (например, отчетность критична в конце квартала)
Не спрашивайте у бизнеса "какой нужен RTO?", спрашивайте "сколько вы потеряете, если система не будет работать час/день?"
Инвентаризация ресурсов
На этом этапе мы создаем исчерпывающий каталог того, что подлежит защите и восстановлению. Важно документировать не только железо, но и конфигурации, лицензии, зависимости. В результате получаем актуальную базу данных конфигураций (CMDB) или детальную таблица/вики-страницу с полным описанием инфраструктуры. Без этого плана восстановления превращается в "археологические раскопки" посреди ночи.
- Аппаратное обеспечение:
- Серверы физические и виртуальные, СХД, сетевое оборудование.
- Серийные номера, модели, гарантийные обязательства.
- Программное обеспечение:
- ОС, СУБД (версии, редакции).
- Прикладное ПО (ERP, CRM, 1С, документооборот).
- Лицензионные ключи и условия активации на резервной площадке.
- Сетевая инфраструктура:
- Схема сетей (VLAN, подсети).
- Конфигурации межсетевых экранов, балансировщиков, DNS.
- VPN-доступ.
- Данные:
- Расположение критичных баз данных.
- Файловые хранилища (с разделением по важности).
- Схемы резервного копирования (где хранятся копии, политики хранения).
Определение RTO и RPO
Используя полученные предыдущие данные формализуем требования к восстановлению в измеримых величинах.
Для каждого критичного сервиса (из этапа 1) устанавливаем:
- RTO — максимальное время простоя.
- RPO — максимальный возраст данных после восстановления.
Проверяем техническую реализуемость: может ли текущая архитектура (каналы связи, мощность резервной площадки) обеспечить заявленные цифры? RTO/RPO — это не пожелания, а обязательства. Если бизнес требует RTO=1 час, а восстановление базы данных с ленты физически занимает 4 часа, значит, нужно менять архитектуру (переходить на дисковые снапшоты или репликацию).
Согласовываем эти цифры с бизнесом и фиксируем в SLA (соглашении об уровне обслуживания). Получаем таблицу соответствия "Сервис — RTO — RPO" (SLA Matrix), утвержденная руководством.
Выбор команды реагирования
В кризисной ситуации не должно быть вопроса "кто главный?". Роли распределяются заранее, с назначением персональной ответственности и резервов сотрудников.
Составляем матрицу ролей:
- Роль
- За что ответственный
- Кто исполнитель
Заполняем эту таблицу контактами с ФИО, телефонами, email, мессенджерами и дублерами. DRP содержит персональные данные исполнителей, помните об этом. Светить этими данными за пределы организации нельзя.
Этот документ должен храниться в доступном месте, не на основном сервере. На внешней площадке.
Документирование процедур
Пишем инструкции для восстановления сервисов. Технические инструкции должны быть настолько детальными, чтобы восстановление мог выполнить инженер с минимальным знанием контекста (или даже подрядчик в критической ситуации).
Структура технического runbook для каждого сервиса:
- Пререквизиты: что должно быть готово ДО начала восстановления (например, "поднята базовая сеть", "получен доступ к хранилищу бэкапов").
- Порядок действий (пошагово):
- Команды для запуска скриптов.
- Последовательность загрузки серверов (какой сервер зависит от какого).
- Параметры конфигурации (IP-адреса резервной площадки, имена хостов).
- Ссылки на образы, бэкаапы, дистрибутивы.
- Проверка работоспособности: как убедиться, что сервис восстановлен корректно? (Тестовые запросы, чек-лист валидации).
- Процедура возврата (failback): Как вернуть нагрузку на основную площадку после устранения аварии.
Получаем библиотеку runbook'ов (в Confluence, SharePoint или Git), доступную офлайн. Каждая инструкция должна быть проверена на практике. Документируйте не только успешный сценарий, но и типичные ошибки и способы их решения.
Коммуникационный план
Восстановление систем бесполезно, если никто не знает, что происходит, и когда можно вернуться к работе. Коммуникационный план синхронизирует действия ИТ и бизнеса. Составляем план:
- Каналы оповещения:
- Основной канал (например, корпоративный мессенджер).
- Резервный канал (SMS-рассылка, email на личную почту) — на случай падения основного канала.
- Шаблоны сообщений:
- Уведомление о начале аварии: "Система Х недоступна, ведутся работы, следующий апдейт через 30 минут".
- Промежуточные статусы: Раз в N времени.
- Уведомление о завершении: "Работа систем восстановлена, данные актуальны на момент ЧЧ:ММ".
- Матрица оповещения (кто кого оповещает):
- Техническая команда → Координатор DR.
- Координатор DR → Руководство.
- Руководство → Клиенты/Партнеры (через PR).
- Координатор DR → Все сотрудники (через HR/Офис-менеджера).
Итог: готовая таблица коммуникаций и набор текстов, которые не нужно придумывать в стрессовой ситуации.
Итоговый чек-лист этапов
- Проведен BIA, определены приоритеты сервисов
- Составлена полная инвентаризация ИТ-активов и зависимостей
- Утверждены метрики RTO/RPO для каждого критичного сервиса
- Назначена команда DR с ролями и контактами (включая backup)
- Написаны и проверены технические runbook'и (доступные офлайн)
- Разработан и протестирован коммуникационный план
- Документ DRP утвержден и хранится в надежном месте (вне основной инфраструктуры)
Тестирование DRP
План, который не проверен на практике — макулатура.
Мы тратим время на разработку идеального Disaster Recovery Plan, согласовываем его со всеми инстанциями, торжественно утверждаем у руководства, после чего кладём на полку и забываем о его существовании до первого реального сбоя. В такой ситуации наличие плана создает лишь опасную иллюзию защищенности.
Когда случается настоящая катастрофа, выясняется, что пароли от резервной площадки устарели, в схеме сетевых соединений ошибка, а ответственный инженер уволился полгода назад, и его никто не заменил.
Именно поэтому тестирование является не просто рекомендацией, а обязательным и регулярным процессом в жизненном цикле DRP. Оно позволяет выявить слабые места, проверить актуальность документации, обучить персонал и отточить взаимодействие между командами до автоматизма. Это стоит денег и времени.
Разделяют три вида тестирования, в зависимости от возможностей и сложности выполнения:
- Desk Check (бумажная проверка)
- Частичное тестирование (восстановление одной системы)
- Полномасштабное учение (full-scale test)
Запланируйте учения и проведите их.
Чек лист DRP
- Проведен аудит ИТ-инфраструктуры
- Определены RTO/RPO
- Назначены ответственные
- Выбрано хранилище для резервных копий (географически удаленное)
- Проведено первое тестирование
Поздравляем, вы внедрили DRP.
Заключение
DRP — это не просто документ для галочки, а страховка бизнеса. Наличие четкого, проверенного плана действий превращает катастрофу в регламентные работы, пусть и внеплановые.
Нельзя объять необъятное и впихнуть невпихуемое. Не пытайтесь задокументировать восстановление всей инфраструктуры сразу — это займет месяцы, а результат устареет быстрее, чем будет дописан. Начните с малого — задокументируйте восстановление самого критичного сервера, а затем расширяйте план. Лучше иметь работающий план для одного сервера, чем красивую, но мертвую концепцию для целого дата-центра.






















