


Крупнейший сбой Atlassian. Ориентировочно 400 компаний и 50000 - 800000 пользователей потеряли доступ к JIRA, Confluence, OpsGenie, странице состояния JIRA и другим облачным сервисам Atlassian.
2 недели с 4 по 17 апреля шло восстановление.
https://jira-software.status.atlassian.com/
Руководители Atlassian 9 дней не признавали сбой, компания хранила молчание. Не с лучшей стороны себя показали, однозначно.
Хронология событий
День 1 (4 апреля)
Всё сломалось.
День 2 (5 апреля)
Atlassian замечает инцидент и начинает отслеживать его на странице статуса. Работают над исправлением, но не указывают причину.
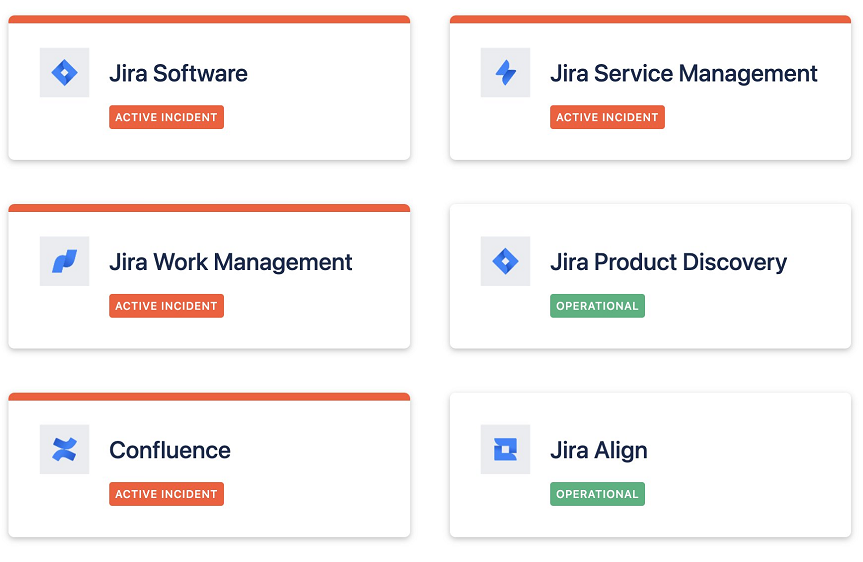
День 3 (6 апреля)
Atlassian публикует одно и то же обновление каждые несколько часов.
We continue to work on the resolution of the incident...
День 4 (7 апреля)
Atlassian признаёт проблему в твиттере. После этого 5 дней не публикует записи.
While running a maintenance script, a small number of sites were disabled unintentionally. We’re sorry for the frustration this incident is causing and we are continuing to move through the various stages for restoration.
День 5, 6, 7 (8-10 апреля)
Тишина. Atlassian публикует каждые несколько часов:
We continue to work on partial restoration to a cohort of customers.
We have started successfully restoring sites and continue to work on restoration to a wider cohort of customers.
The team is continuing the restoration process through the weekend and working toward recovery.
We continue to work 24/7 to restore service to affected customers.
Новости о сбое в работе Atlassian появились в Hacker News и на Reddit.
День 8 (11 апреля)
Очень популярен комментарий от пользователя, который представился бывшим сотрудником Atlassian.
This does not suprise me at all. I came by acquisition years ago, and was wondering when something would like this happen. They've deleted internal Slack, internal wiki before. Nobody cares about stability or scalability at Atlassian, their incident process and monitoring is a joke. More than half of the incidents are customer detected.
День 9 (12 апреля)
Atlassian делает рассылку клиентам, суть которой сводится к тому, что всё очень сложно, и восстановление может продлиться до 2 недель(!).
Обновление статуса инцидента: восстановлена функциональность для 35% клиентов.
Впервые с начала инцидента Atlassian выступает с заявлением. Они утверждают, что сотни инженеров работают над проблемой. Руководитель отдела разработки Стивен Дизи публикует вопросы и ответы об активном инциденте в сообществе Atlassian.
Названа причина проблемы. Инцидент не связан с кибератакой или сбоем масштабирования систем. Всего лишь был удалён устаревший плагин "Insight — Asset Management". Был запущен скрипт, который должен был удалить все данные о клиентах плагина, вместо этого были удалены все данные клиентов, использующих плагин.
Становится понятно, что ребята из Atlassian сами случайно потёрли данные. Отлично, но почему восстановление будет длиться две недели? Ведь Atlassian заявляет, что может восстановить данные за считанные часы.
- Atlassian действительно может восстановить все данные до контрольной точки за считанные часы.
- Проблема в том, что при этом "восстановится" предыдущее состояние остальных клиентов, т.е. они потеряют данные.
- Восстанавливать данные каждого клиента нужно вручную. У Atlassian нет инструментов, чтобы делать это массово.
День 10 (13 апреля)
Восстановлена функциональность для 45% клиентов.
День 11 (14 апреля)
Восстановлена функциональность для 49% клиентов. Процесс восстановления данных частично автоматизирован.
День 12 (15 апреля)
Восстановлена функциональность для 62% клиентов.
День 13 (16 апреля)
Восстановлена функциональность для 85% клиентов.
День 14 (17 апреля) — прошло две недели
04:19 UTC: Восстановлена функциональность для 99% клиентов.
21:48 UTC: Работа восстановлена.
Клиенты имеют право на 50% скидку на свой следующий ежемесячный счет.
На 18 апреля состояние Atlassian:
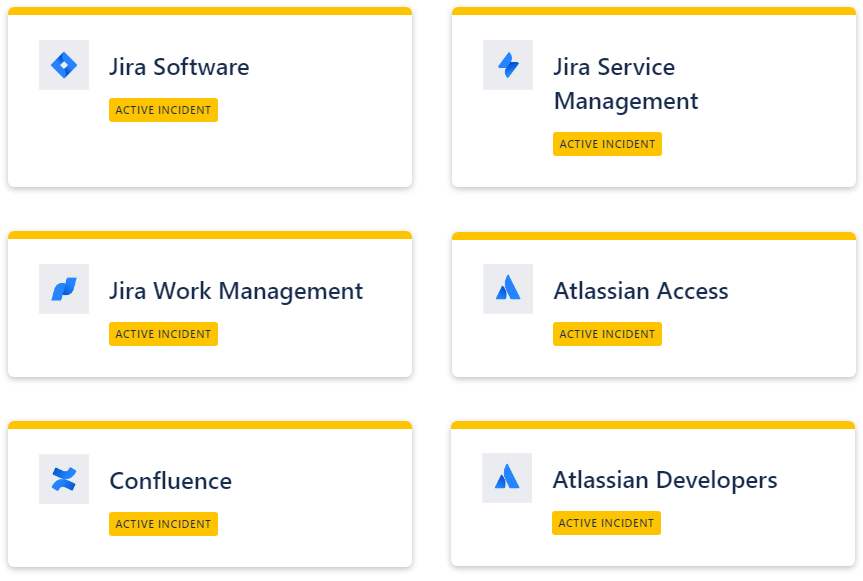
Ну что можно сказать, не храните яйца в одной корзине... Если учесть что ранее Atlassian приостановила продажи в России и заблокировала госаккануты, то не храните данные в Atlassian.




















