


Если вы используете сервер HPE Proliant с RAID контроллером без батарейки, то при потере электропитания можете получить неприятную ошибку.
1779-Slot 1 Drive Array - Replacement drive(s) detected OR previously failed drive(s) now appear to be operational: <список дисков> Logical Drive(s) disabled due to possible data loss. Action: Resolve any issues that disabled drive. Restore data from backup if drive(s) replaced.
Дальше могут быть варианты. Могут быть предложения продолжить без дисков или согласиться с потерей данных и восстановить массив.
Select F1 to continue with logical drive(s) disabled
Select F2 to accept data loss and to re-enable logical drive(s)Или может быть вариант, где можно перейти к меню с просмотром проблем при работе системы.
Обычно сервер продолжает грузиться и, если на массиве была система, загрузиться не может.
Собственно, причина ошибки простая. RAID контроллер зафиксировал подключение дисков после сбоя электропитания. В этом случае данные в массиве могут быть не согласованы, что-то могло не записаться.
Если согласиться с "data loss and to re-enable logical drive(s)", то массив или соберётся или нет. Как правило, после обычного отключения питания массив собирается.
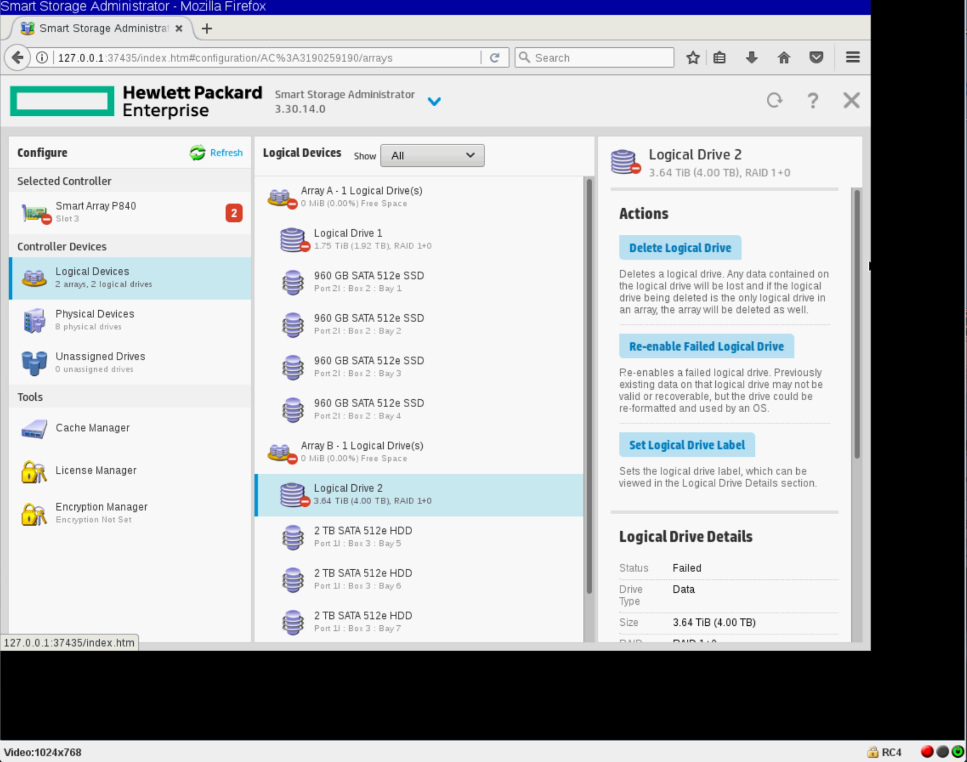
Если зайти в SSA и посмотреть состояние массивов, то увидим страшную ошибку:
...All data on this drive has been lost...
Могли бы написать что-нибудь менее страшное.

В опциях логического диска есть вариант Re-enable Failed Logical Drive. Но я не люблю ей пользоваться.
Или выбираю при загрузке вариант:
Select F2 to accept data loss and to re-enable logical drive(s)Или проваливаюсь в список проблем System Health.
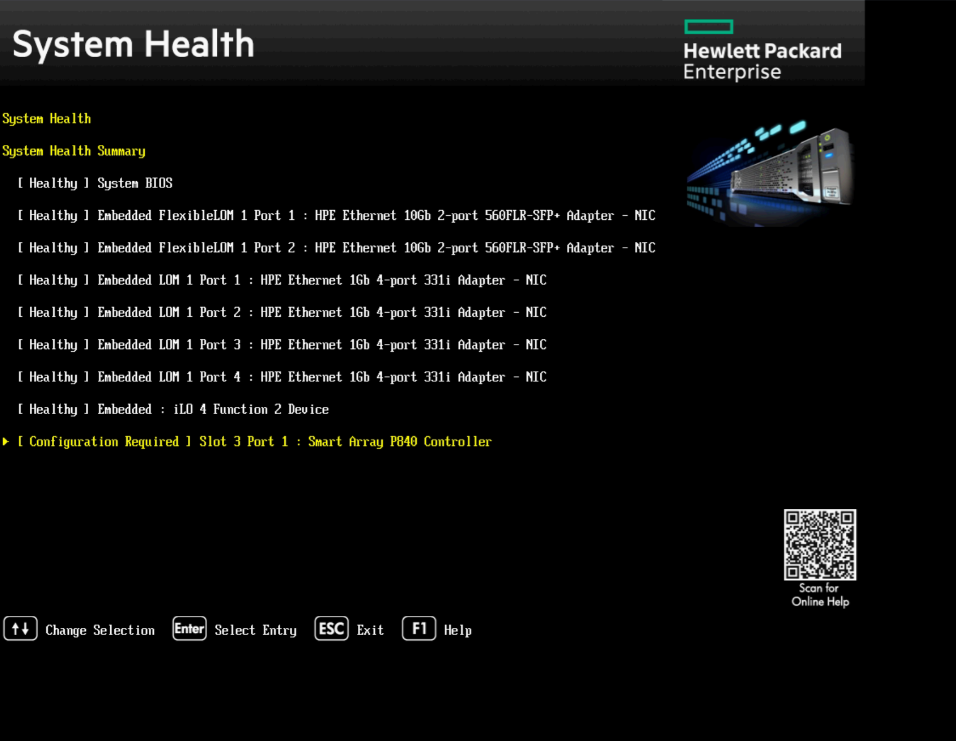
Видим проблему с контроллером:
[ Configuration Required ] Slot 3 Port 1 : Smart Array P840 ControllerПроваливаемся внутрь.

Видим подробную ошибку. Проваливаемся в пункт:
Health Status: Configuration Required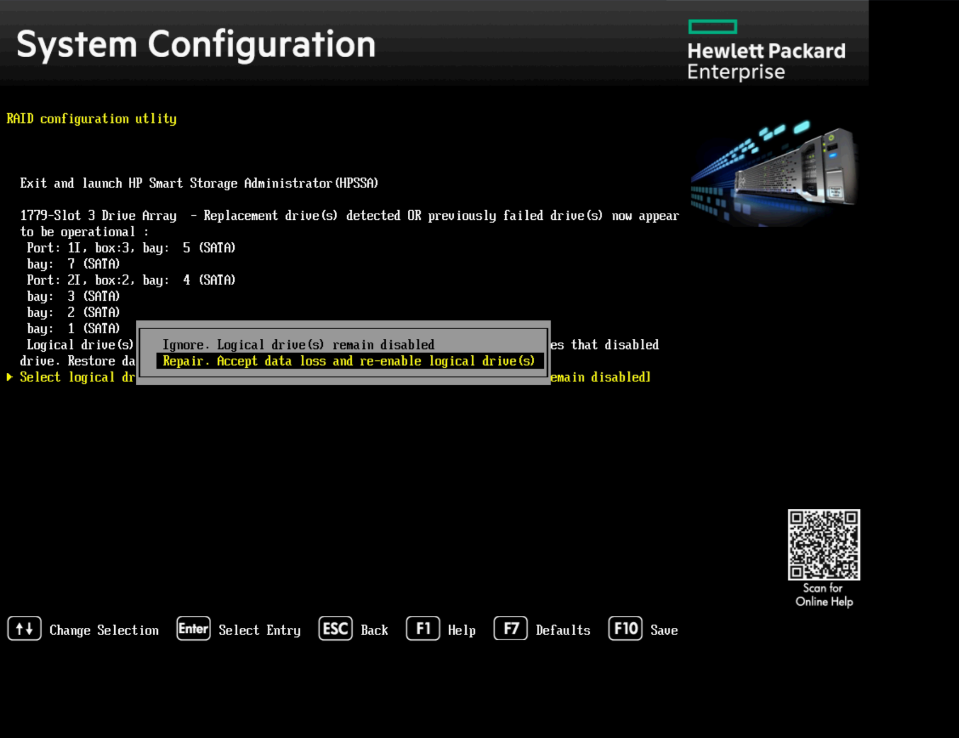
Из предложенный вариантов выбираем Repair. Если повезёт, то массив восстановится и всё будет работать нормально. Даже если всё восстановится, это звоночек.
Что можно предложить ещё?
Как минимум можно задуматься:
- Не купить ли батарейку для контроллера?
- Не использовать ли разные электрические вводы?
- Не поставить ли ИБП?
- Не проверить ли как работает система резервного копирования, если она есть?
- Не забэкапить ли данные сервера, если бэкапов нет?
- Не поставить ли второй резервный сервер на другую площадку?
- Не рассмотреть ли резерв в облаке?






















