


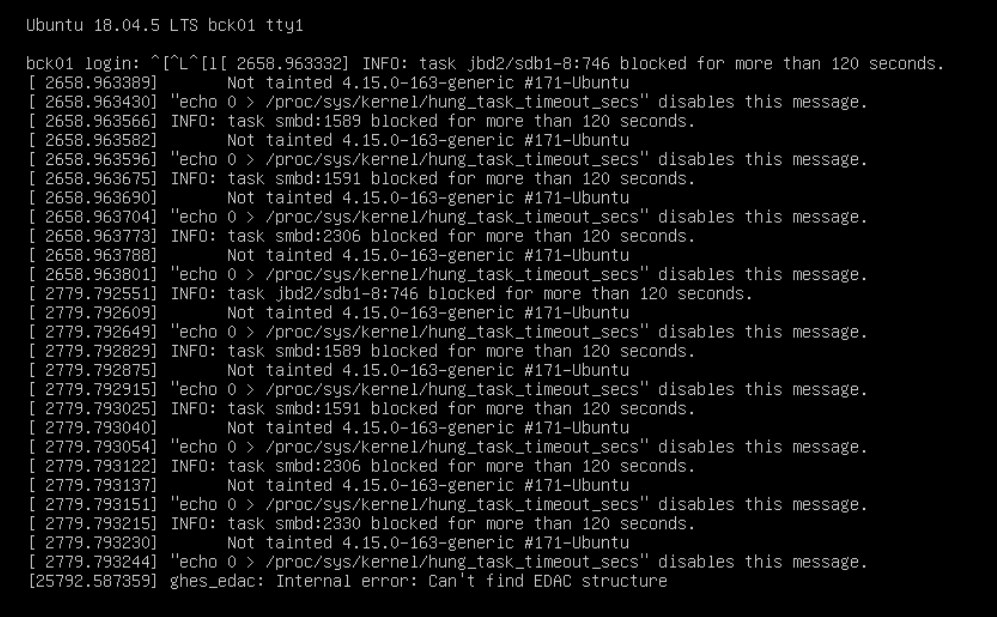
Интересный кейс произошёл с сервером Dell PowerEdge R740xd2. В какой-то момент в операционной системе Ubuntu 18.04 LTS появились ошибки вида:
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disabled this message.
INFO: task smbd:1589 blocked for more than 120 seconds.
Полез смотреть логи iDRAC, а там:
The memory health monitor feature has detected a degradation in the DIMM installed in DIMM_A1. Reboot system to initiate self-heal process.
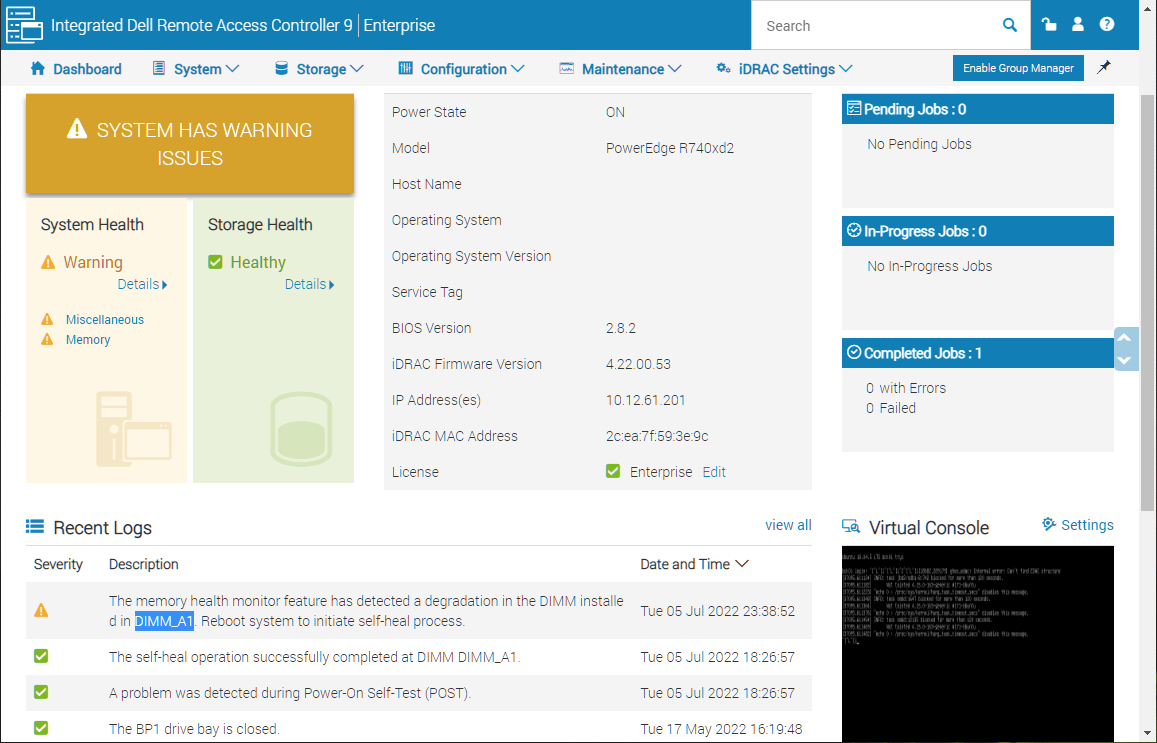
Произошла деградация планки памяти, что явно видно в таймаутах ОС, iDRAC предлагает перезагрузить сервер, чтобы выполнить самовосстановление. Хорошо, перезагружаю сервер.
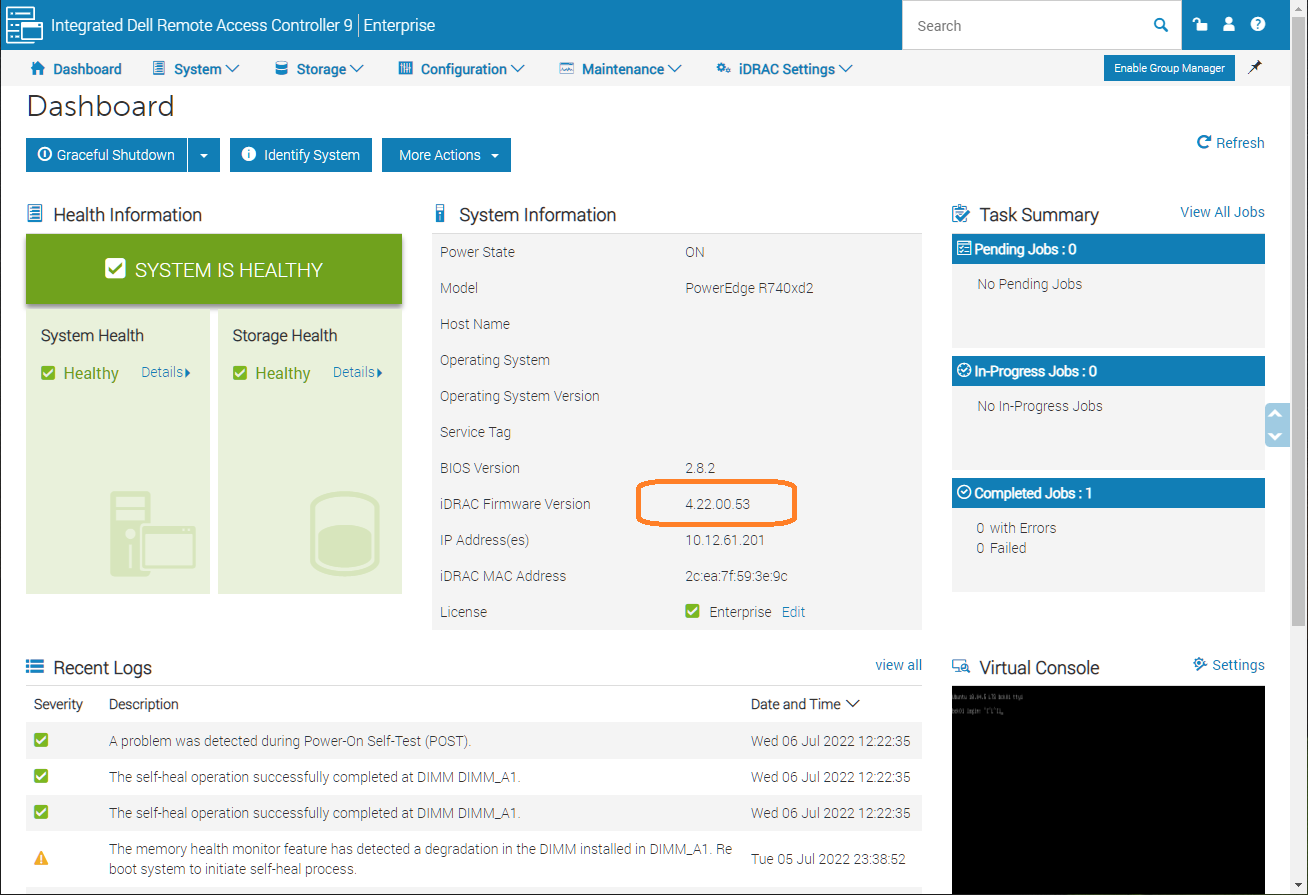
После перезагрузки в логах:
The self-heal operation successfully completed at DIMM_A1.
Ошибки памяти могут быть вызваны большим количеством факторов. Классический случай, когда один бит DRAM автоматически переходит в противоположное состояние 0 ⇔ 1. Ошибка может быть вызвана перегревом, старением памяти, производственным дефектом, механическим повреждением, космическими лучами. Эти ошибки называют исправимыми или корректируемыми, потому что их можно легко исправить обновлением состояния памяти. С современных планках памяти коррекция ошибки происходит автоматически благодаря механизму ECC.
ECC-память (error-correcting code memory, память с коррекцией ошибок) — тип компьютерной памяти, которая автоматически распознаёт и исправляет спонтанно возникшие ошибки битов памяти.
Самым часто используемым кодом с коррекцией ошибок является код Хэмминга. Так, но сейчас не об этом. В общем, при коррекции ошибки система ничего не замечает, а в память записывается информация об общем количестве ошибок.
Случаются и некорректируемые ошибки, когда внутри одного блока памяти случаются сразу две ошибки. ECC в данном случае не поможет. Неисправимая ошибка памяти может привести к сбою системы (перезагрузка) или приложения (BSoD). Часто исправимые ошибки предупреждают о приближающихся неисправимых ошибках.
Непонятно что произошло в моём случае на сервере, что потребовало перезагрузку, возможно, как раз неисправимая ошибка.
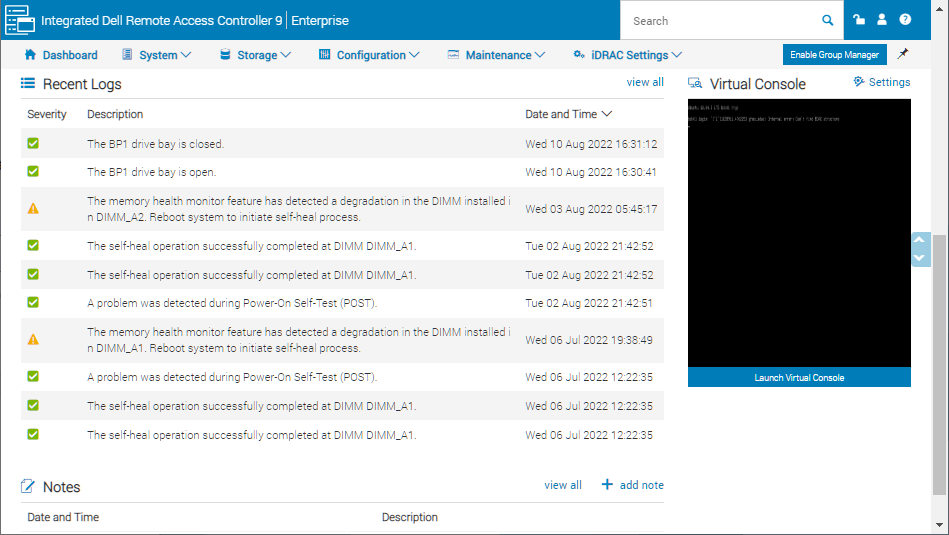
Через месяц ошибка повторилась, но уже на втором модуле памяти. Перезагрузка.
Проблема оказалась серьёзнее, в момент ошибки сервер тормозит и глючит. Но планка-то уже другая, так что часть возможных причин проблемы можно отбросить. Брак целой партии планок памяти? У меня были случаи, когда в поставке сразу две планки памяти оказались битые. Потом снова ошибка на DIMM_A1...
Заказали две новых планки памяти. Пока заказывали память, на втором сервере произошла такая же ошибка. Это уже третья планка памяти. Что-то здесь не так.
Техподдержка Dell больше недоступна, действуем как обычно. Начинаем с обновлений, благо, их можно достать.
Текущая версия iDRAC, как видно из скриншотов, 4.22.00.53. Обновляю до версии 6.00.02.00.
iDRAC 9 v 6.00.02.00 от 17 августа 2022 г
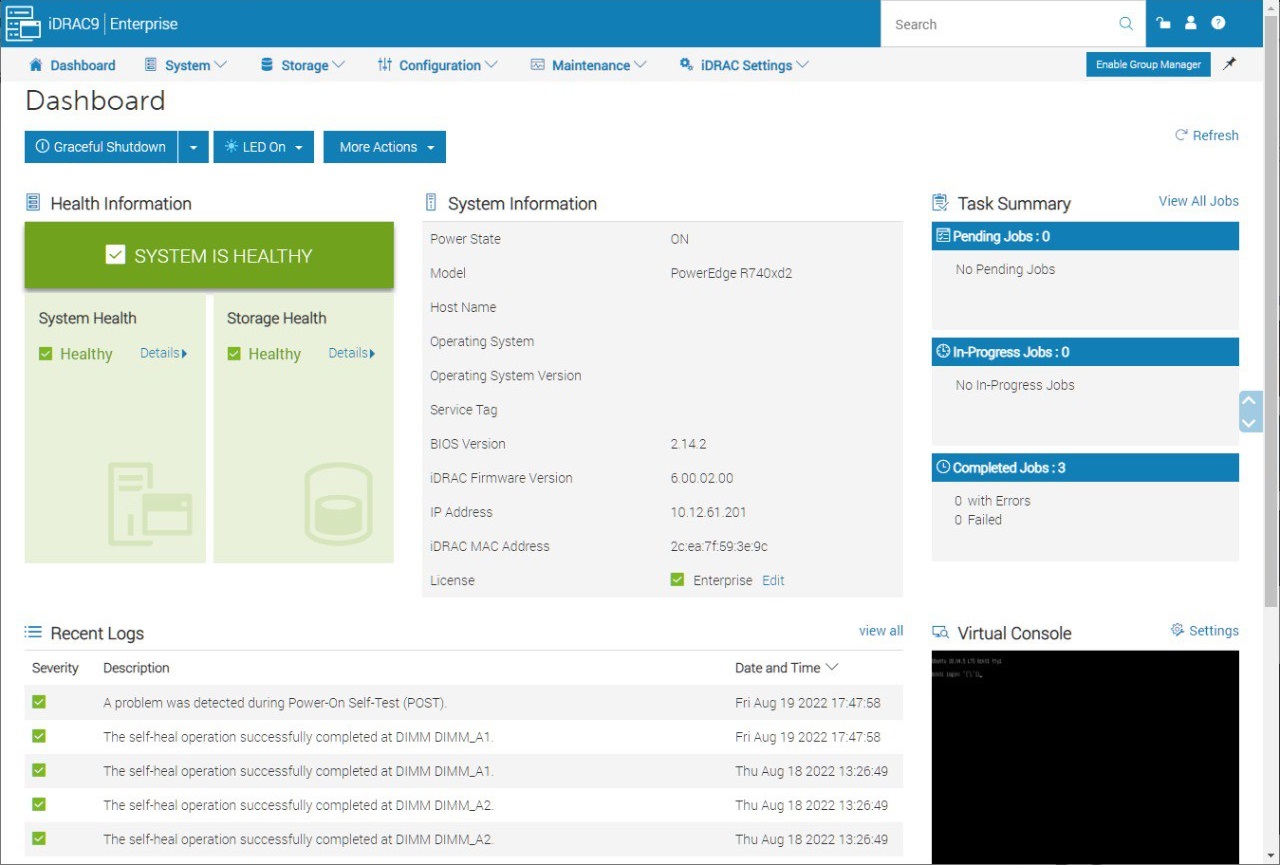
После перезагрузки снова:
The self-heal operation successfully completed at DIMM_A1.
И всё, прошло 4 месяца — ошибок нет. Теперь у меня два рабочих сервера и две планки памяти в запасе.




















