


В ESXi можно поймать ошибку:
Lost access to volume 60f0253c-f3541c40-5db8-48df371f5c50 ( STORAGE ) due to connectivity issues. Recovery attempt is in progress and outcome will be reported shortly.
Это может быть информационное сообщение или предупреждение.
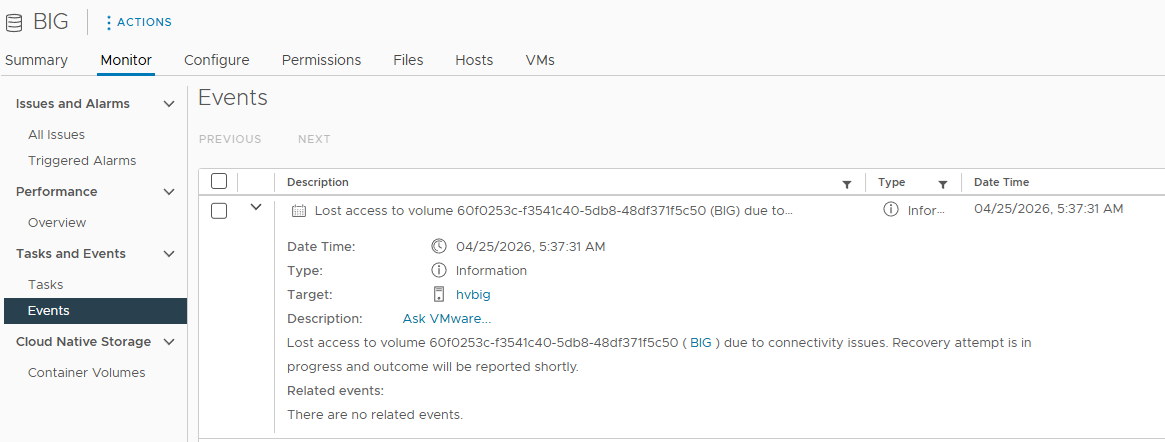
Проблема может проявляться по-разному. Виртуальные машины могут стать недоступны. Или соединение с хранилищем может восстановиться бессимптомно. Ошибка может быть разовой или проявляться постоянно. Если ошибка возникает постоянно или периодически, то с проблемой следует разобраться.
Почему происходит отключение хранилища?
Хранилища данных VMFS отслеживаются с помощью сигналов heartbeat, которые генерируются хостами в виде операций записи примерно каждые 3 секунды на тома VMFS. Каждый хост ESXi, имеющий доступ к хранилищам данных VMFS, ожидает завершения операций ввода-вывода этого сигнала в течение 8 секунд. Если операция ввода-вывода heartbeat не завершается в течение 8 секунд, происходит тайм-аут и отправляется следующий сигнал. Если общее время выполнения операций ввода-вывода heartbeat превышает 16 секунд, хранилище данных помечается как отключенное, и hostd создает сообщение журнала "Lost access to volume", отражающее эту ситуацию.
После того как хранилище данных VMFS помечено как отключенное, ESXi продолжает отправлять операции ввода-вывода «сердцебиения» на это хранилище примерно каждую секунду до восстановления соединения. Если какая-либо операция heartbeat завершается успешно, хранилище данных снова помечается как подключенное, и хост ESXi возобновляет обычный ввод-вывод.
Причина может быть в высокой нагрузке на хранилище, каналы связи, либо из-за неисправного оборудования.
Сигнал Heartbeat в VMFS
VMFS использует дисковый механизм heartbeat (HB) для индикации активности хостов, работающих с файловой системой. Все хосты, использующие общее хранилище, применяют ATS для обновления своего HB в определенной области на диске, чтобы показать, что они работают.
ATS — это аббревиатура от Atomic Test and Set (Атомарное Тестирование и Установка). Это протокол блокировки, который VMware называет "аппаратно-ускоренной блокировкой" (Hardware Assisted Locking)
Простыми словами, ATS — это эффективный способ для ESXi-хостов договариваться друг с другом о том, кто и какие данные записывает в общее хранилище (datastore), не мешая работе друг друга.

Каждый хост, использующий том VMFS, имеет свой собственный слот heartbeat (размером 1 сектор) и обновляет его в Heartbeat Region, как показано на картинке.
Более подробно можно узнать в статье:
VMFS Heartbeat and usage of ATS
Что делать?
Если ошибка периодическая, то следует проверить, какие задачи запускаются на хранилище в этот период времени. Из-за большой нагрузки от регламентных операций и массовых операций ввода-вывода хранилище может стать временно недоступным. В этом случае следует пересмотреть расписание регламентных работ.
Нагрузку может создавать какая-нибудь виртуальная машина, возможно, её следует смигрировать на другое хранилище. У меня была именно эта проблема.
Проверьте настройки RAID массива, который используется на хранилище. Возможно, при его создании забыли включить кэширование. Включение кэширования на контроллере или использование SSD в качестве кэша может исправить ситуацию.
Проверьте состояние RAID массива, RAID контроллера и дисков. Например, при выходе из строя диска в RAID5 массиве, нагрузка на хранилище может возрасти.
Если хранилище подключено по iSCSI, проверьте, не проходит ли трафик ESXi и iSCSI через одну и ту же подсеть. Их лучше разделять на физическом уровне.
Проверьте оборудование на неисправности.
Повреждение Heartbeat Region также может влиять на работу.
Обновление драйверов RAID контроллера может исправить некоторые программные ошибки, которые могут приводить к таким ошибкам. К примеру, такие проблемы были обнаружены на RAID контроллере P410 с использованием SPARE диска на сервере DL180G6. Каждые 5 минут при обращении к SPARE диску RAID контроллер подвисал. Обновление драйвера до версии .60 исправило проблему.
Если проблема с путями до FC или ISCSI дисков, может помочь Rescan all HBAs в Configuration-Storage-Rescan All. Команда выполняет сканирование всех ваших datastore и lun.
Возможны и другие проблемы, не оставляйте ошибку "Lost access to volume due to connectivity issues" без внимания, даже если всё продолжает работать.





















