


История о том как я потратил сутки на внедрение на сайт морфологического поиска. И-таки внедрил, но для этого пришлось преодолеть поле граблей. Много работы — много текста.
Я не самый великий разработчик сайтов на Drupal, поскольку не занимаюсь этим постоянно. Но раз движок моего сайта на Drupal, то приходится быть в курсе дела. Кстати, сайт прошёл путь от Drupal 7 → 8 → 9 и с каждым разом становился всё лучше. По крайней мере, мне хочется на это надеяться.
Итак, надоело мне искать на сайте нужную статью, пытаясь угадать точное слово в названии:
- Как там было? "Установка Windows Server"?
- Нет, кажется "Устанавливаем Windows Server"!
- Странно, не находит. Может, просто "Windows Server?
- Или "Устанавливаю Windows Server", или "Установил Windows".
- Блин, забыл.
А потом мне написал знакомый, он тоже не смог найти нужную ему статью, хотя статья точно была. Пришла пора внедрять морфологический поиск.
Морфологический поиск (стемминг) — принцип поиска, реализуемый в алгоритмах поисковых систем. Он используется для поиска страниц, соответствующих морфологическим словоформам запроса.
Принцип такого поиска простой. Статьи сайта помещаются в табличку-индекс, в которой все слова текста нормализуются, приводятся к какой-то общей форме. И поиск уже идёт не по полю статьи, а по полю с нормализованным текстом.
Сразу скажу, я когда-то давно принимал участие в проектах одной из российских поисковых систем. И лет двадцать назад я видел как был реализован механизм морфологического поиска, вот там действительно все слова приводились к нормальной форме в соответствии с правилами русского языка. А в Drupal и используемых мной модулях нормализация слов устроена немного проще, но не суть важно, поиск работает.
Используемые модули
Для начала отключаем модуль Search. Это необязательно, но у меня есть несколько причин, по которым сделать это нужно. Во-первых, стандартный модуль Search использует путь /search, который я тоже хочу использовать в поиске, так что этот модуль мне мешает. Во-вторых, с внедрением морфологического поиска надобность в модуле Search отпадёт. В третьих, даже если не использовать этот модуль, он продолжит индексировать новые и изменённые статьи и будет лишний раз нагружать систему. Удаляю.
Search API
Устанавливаем модуль Search API. Включаем.
Конфигурация → ПОИСК И МЕТАДАННЫЕ → Search API (/admin/config/search/search-api), здесь добавляем новый сервер.
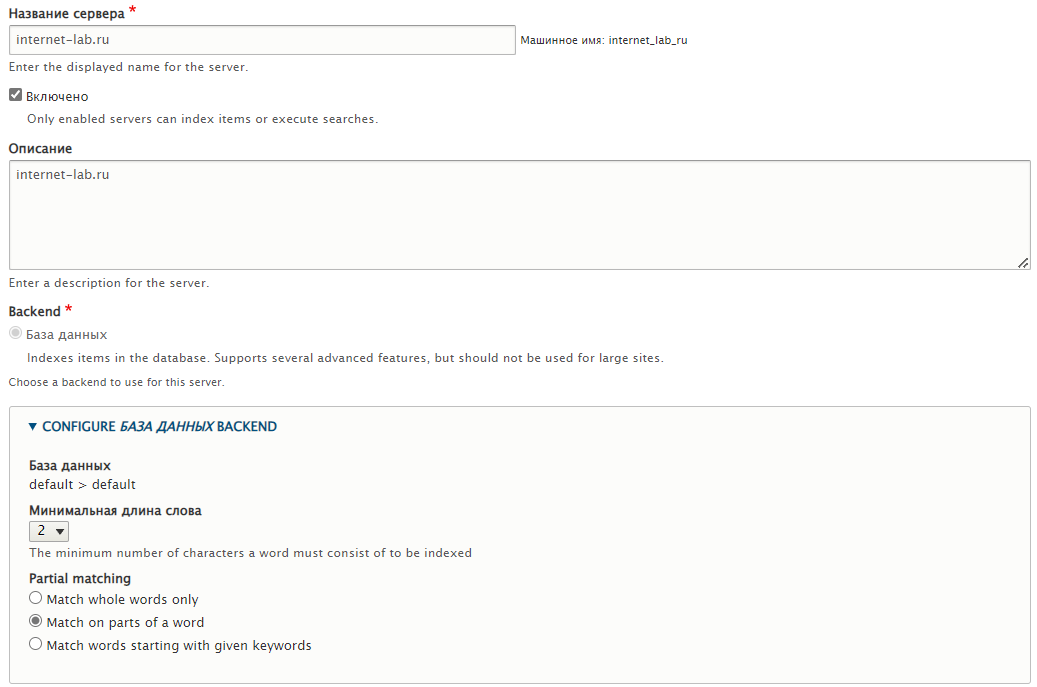
Указываем название, описание. В качестве Backend выбираем базу данных. Указываем минимальную длину слова, по умолчанию 3 символа, я поставил два, индекс станет больше, но мне пригодится. Думаю и с одним символом попробовать, чтобы "Windows 7" нормально находился. Partial matching — выбираю совпадение с частью слова, это усилит возможности поиска.
Конфигурация → ПОИСК И МЕТАДАННЫЕ → Search API (/admin/config/search/search-api), здесь добавляем новый индекс.
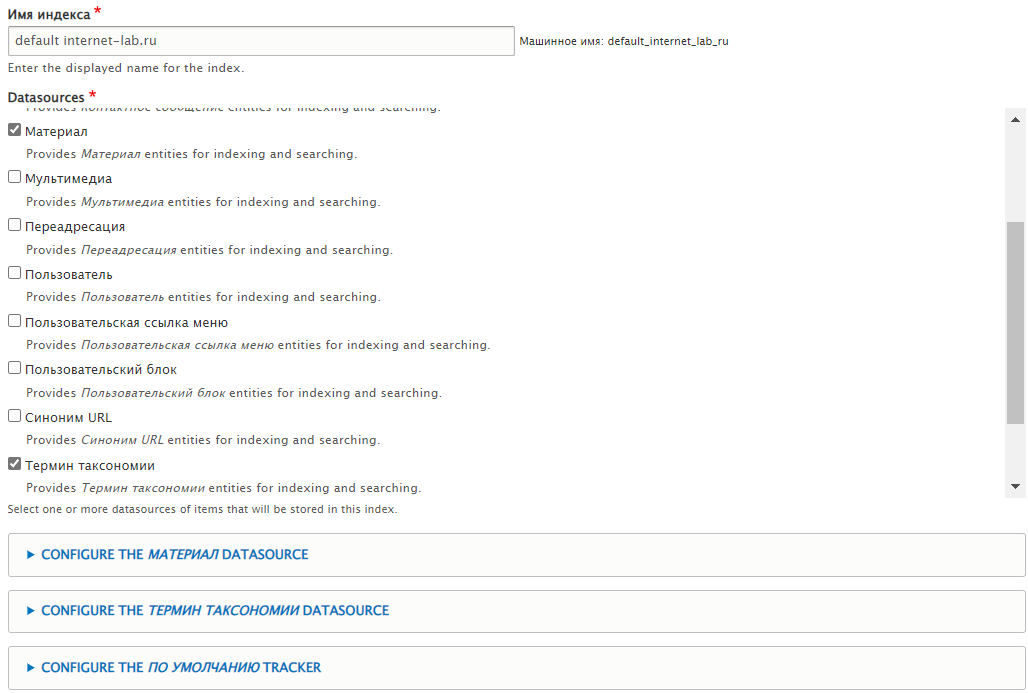
Указываем название индекса. Выбираем что искать, я выбираю Материал (все виды статей, страниц, игр, книг и прочих материалов) и Термин таксономии (теги, авторы игр, издатели игр, типы игр и прочие словари). Далее нужно сконфигурировать выбранные источники поиска. Разворачиваю CONFIGURE THE МАТЕРИАЛ DATASOURCE.
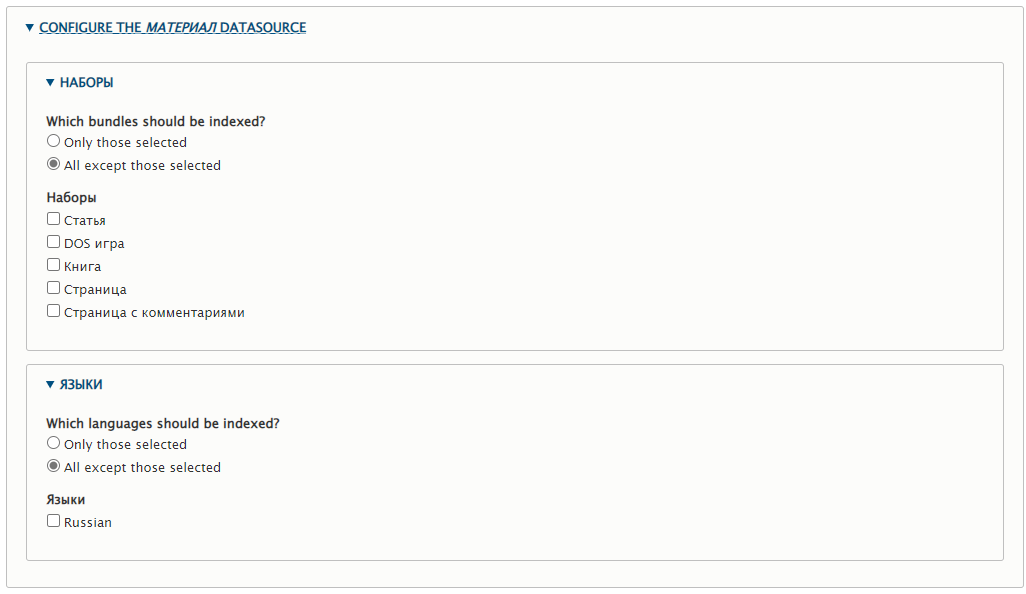
НАБОРЫ — здесь можно указать типы материалов, которые попадут в поиск. У меня есть:
- Статья
- DOS игра
- Книга
- Страница
- Страница с комментариями
Можно указать только отмеченные галками "Only those selected", или, наоборот, только не отмеченные галками "All except those selected". У меня выбраны все.
ЯЗЫКИ — соответственно, языки материалов. У меня только Russian.
Разворачиваю CONFIGURE THE ТЕРМИН ТАКСОНОМИИ DATASOURCE.
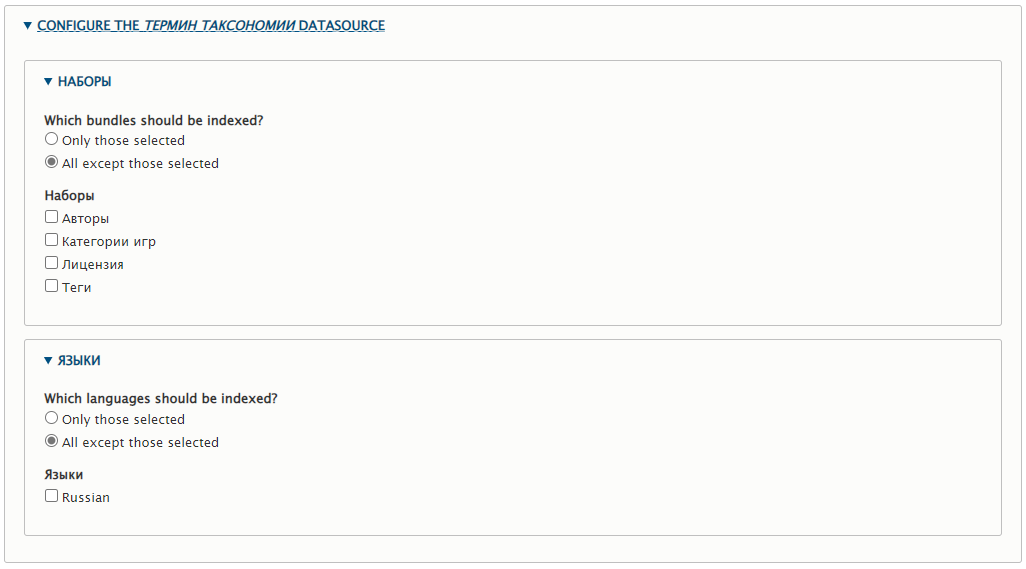
Здесь тот же принцип. Указываем какие термины таксономии индексировать. И язык.
Разворачиваю CONFIGURE THE ПО УМОЛЧАНИЮ DATASOURCE.

Здесь можно выбрать порядок индексации. Индексировать в порядке сохранения элементов или по популярности. Без разницы что выбирать, когда индекс достигнет 100%, все элементы будут проиндексированы. Возможно, это имеет смысл для больших сайтов, чтобы на момент перестроения индекса хоть что-то находилось. Кстати, я заметил, что индексация в Search API работает значительно быстрее чем в стандартном модуле поиска Search.
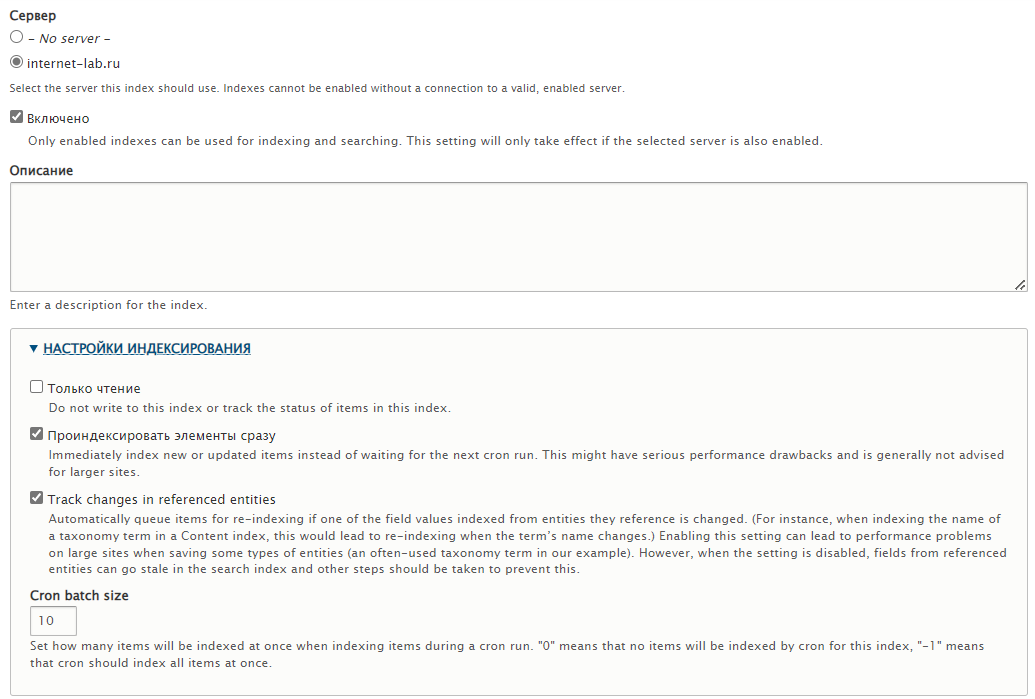
Сервер — указываем сервер, который создавали на предыдущем шаге. Включаем галкой индекс: "Включено". Указываем при желании описание.
Разворачиваю НАСТРОЙКИ ИНДЕКСИРОВАНИЯ. Ставлю галки:
- Проиндексировать элементы сразу
- Track changes ireferenced entities
Cron batch size устанавливаю в 10. Индексироваться будет 10 элементов за раз, чтобы сильно не нагружать сервер.
Сохраняю индекс пока без добавления полей. Мы ещё к нему вернёмся.
Ludwig и Snowball Stemmer
Вот дальше нам надо бы установить Snowball Stemmer, но он для работы использует библиотеку PHP Stemmer, которая устанавливается с помощью Composer. Если у вас есть Composer, то можно пропустить установку Ludwig, но у меня нет Composer. Разработчики Snowball Stemmer не указали способ ручной установки библиотеки PHP Stemmer, приходится теперь корячиться.
Устанавливаем модуль Ludwig. Включаем.
Drupal 9 — модуль Ludwig, ручная альтернатива Composer
Устанавливаем модуль Snowball Stemmer. НЕ ВКЛЮЧАЕМ. Модуль не имеет поддержки Ludwig, поможем ему. Создаём в папке модуля Snowball Stemmer файл ludwig.json с содержимым:
{
"require": {
"voku/portable-ascii": {
"version": "v1.5.6",
"url": "https://github.com/voku/portable-ascii/archive/1.5.6.zip"
},
"voku/portable-utf8": {
"version": "v5.4.51",
"url": "https://github.com/voku/portable-utf8/archive/5.4.51.zip"
},
"symfony/polyfill-intl-grapheme": {
"version": "v1.22.1",
"url": "https://github.com/symfony/polyfill-intl-grapheme/archive/v1.22.1.zip"
},
"wamania/php-stemmer": {
"version": "v2.2.0",
"url": "https://github.com/wamania/php-stemmer/archive/v2.2.0.zip"
}
}
}
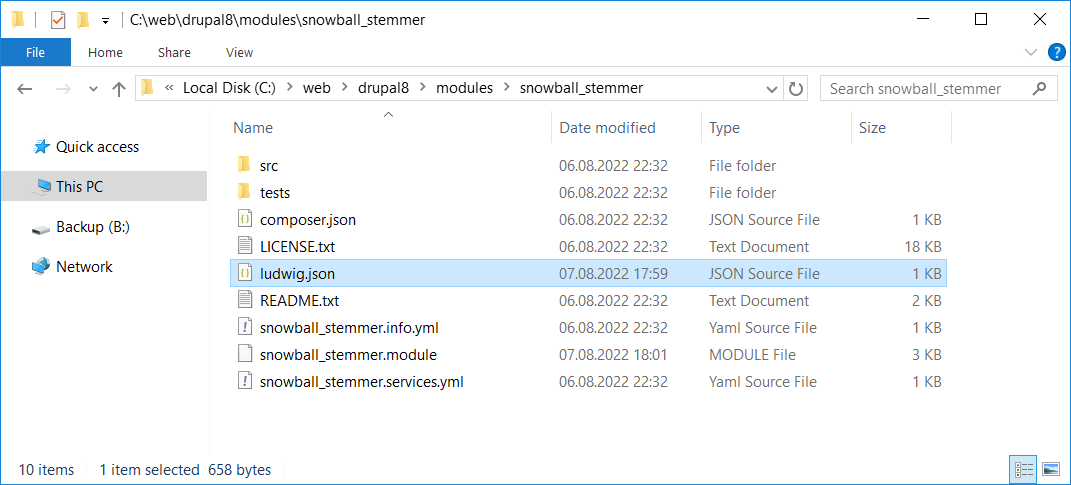
Редактируем snowball_stemmer.module. После строки
use Drupal\Core\Routing\RouteMatchInterface;
вставляем код:
// Ludwig integration for 'files' and 'classmap' autoload resources.
if (\Drupal::hasService('ludwig.require_once')) {
$ludwig_require_once = \Drupal::service('ludwig.require_once');
$ludwig_require_once->requireOnce('voku/portable-utf8', 'bootstrap.php', dirname(__FILE__));
$ludwig_require_once->requireOnce('symfony/polyfill-intl-grapheme', 'bootstrap.php', dirname(__FILE__));
}
Кому лень работать руками, патч здесь:
Snowball Stemmer 2.0.0 - Add Ludwig integration [D9 only] [#3205094] | Drupal.org
Если точнее, то здесь:
https://www.drupal.org/files/issues/2021-03-23/3205094-02.patch
Отчёты → Пакеты (/admin/reports/packages). И модуль Ludwig подсасывает нам все необходимые PHP пакеты и их зависимости. Красота.
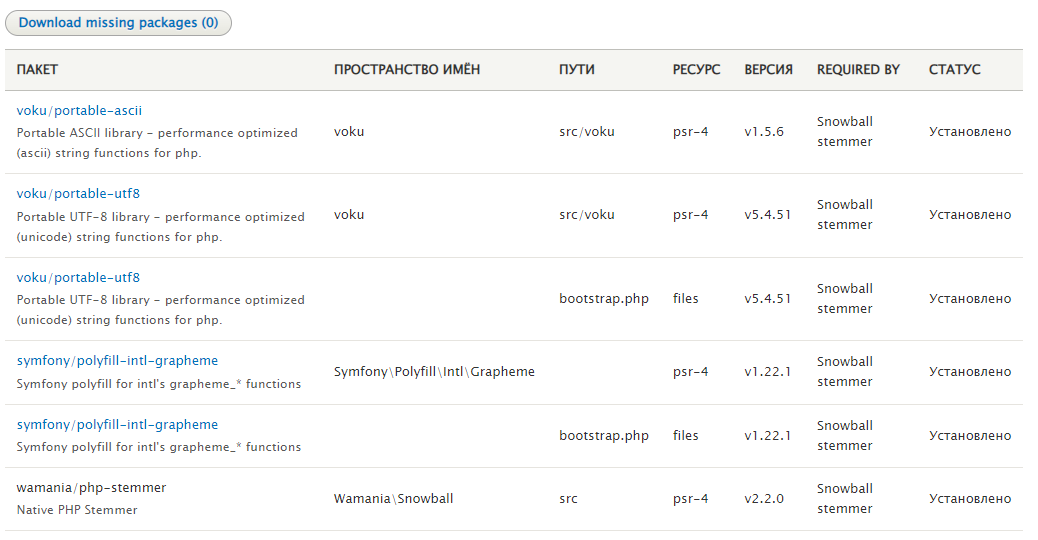
Включаем модуль Snowball Stemmer. На этом наша возня не закончилась. Процессор модуля Snowball Stemmer не появляется в Search API если на сайте отключен английский язык. Это баг:
Processor unavailable when English language is disabled [#3274194] | Drupal.org
Для исправления бага есть патч:
Внимание, в последней версии баг исправлен.
Я правлю вручную. Редактирую файл /src/Plugin/search_api/processor/SnowballStemmer.php. Добавляю в код:
use Drupal\search_api\IndexInterface;
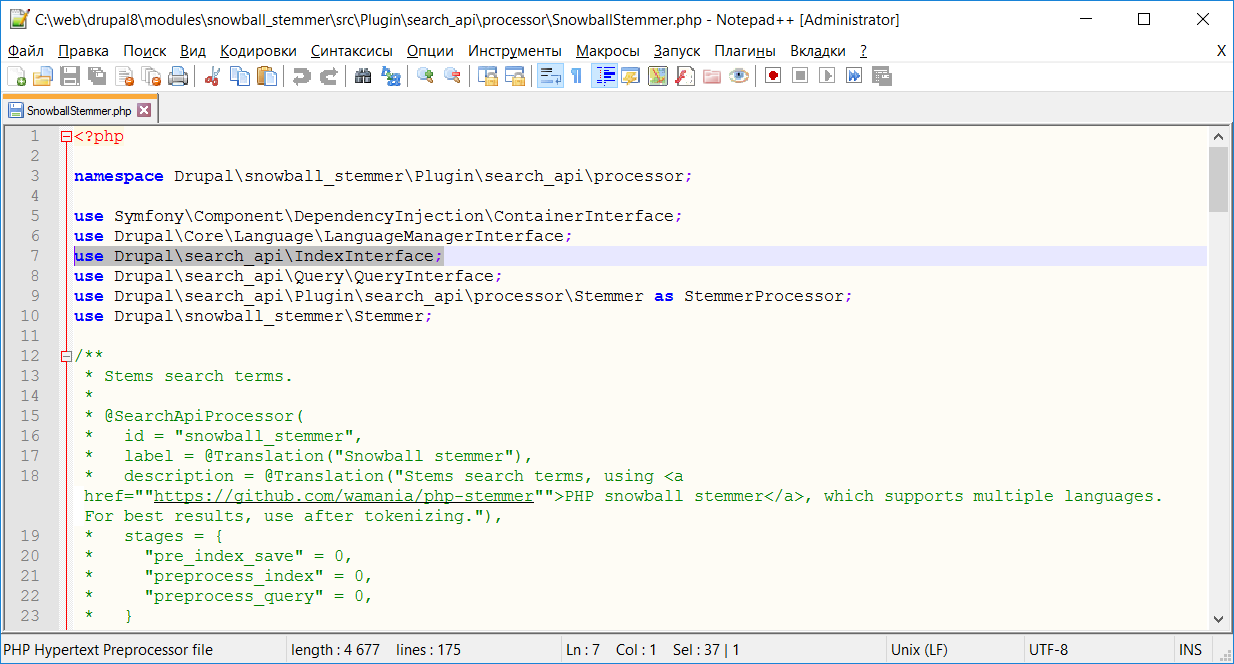
и
/**
* {@inheritdoc}
*/
public static function supportsIndex(IndexInterface $index): bool {
return TRUE;
}
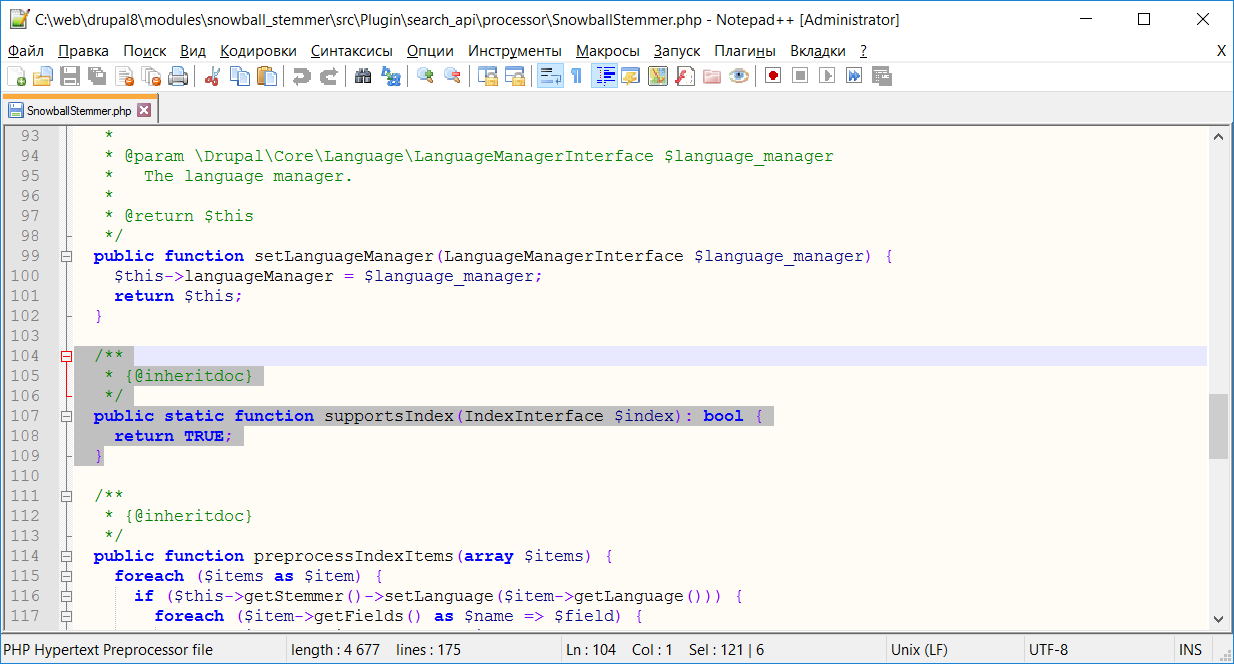
Вот теперь модуль модуль Snowball Stemmer должен заработать как надо.
Search API — редактируем индекс
Конфигурация → ПОИСК И МЕТАДАННЫЕ → Search API (/admin/config/search/search-api), здесь редактируем добавленный ранее индекс.
Здесь нужно добавить поля, по которым будет производиться поиск. Т.е. те, которые нужно индексировать. + Добавить поля.
Индексировать я буду по полям:
- Материал
- Заголовок
- Содержимое
- Термин таксономии
- Название
- Описание
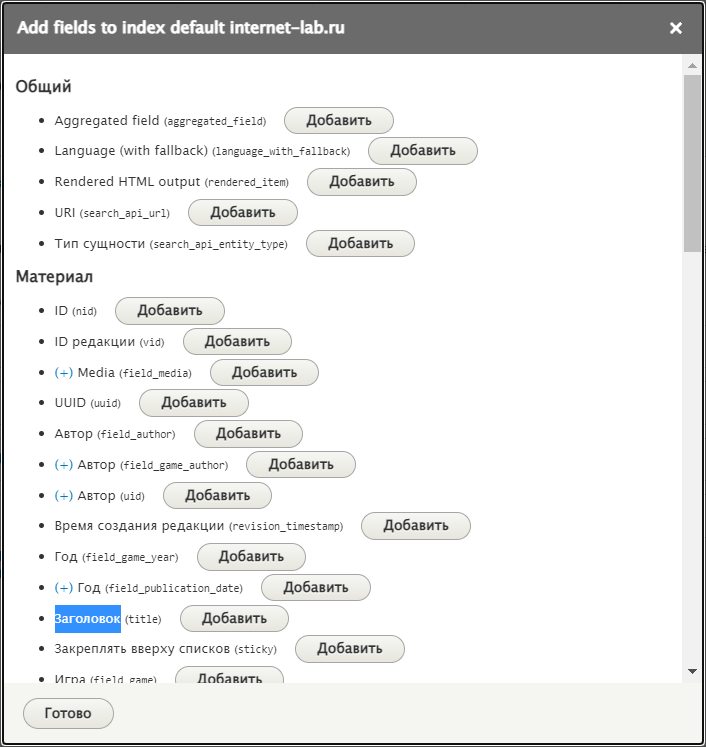
Нахожу в открывшемся списке нужные поля и добавляю каждое.
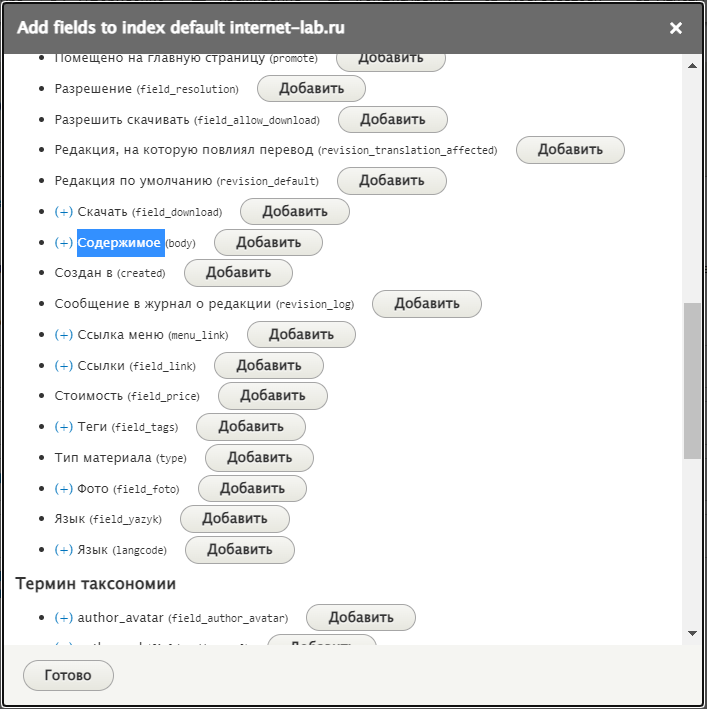
В результате у меня будет осуществляться поиск по названию и по содержимому моих документов.
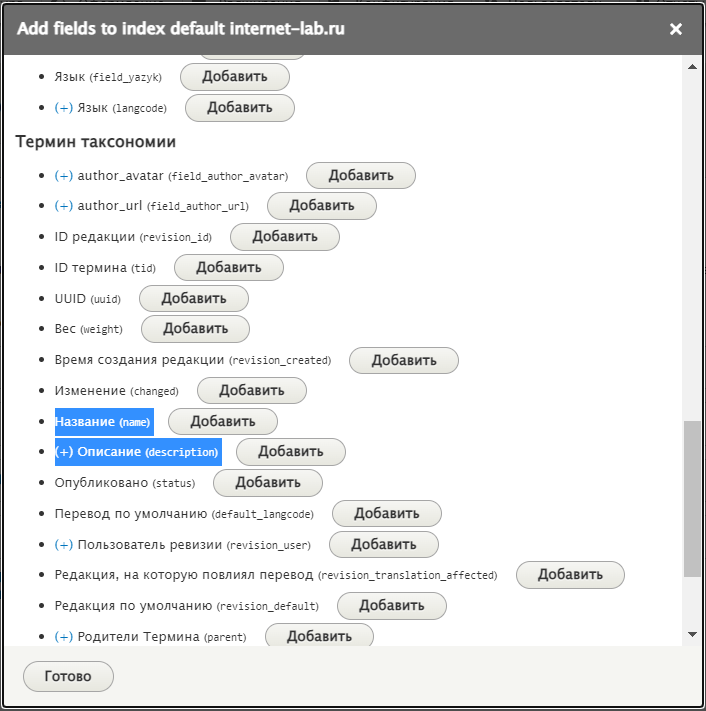
Готово. Автоматически в Материал добавляются некоторые необходимые для индекса поля.
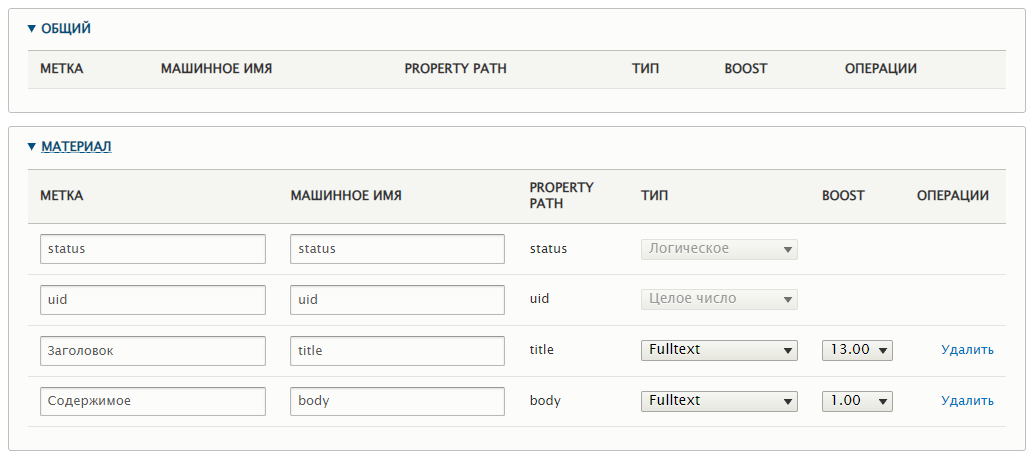
Для заголовка и содержимого статьи устанавливаю тип Fulltext и указываю рейтинг (BOOST). Чем больше число, тем выше в результатах поиска будет появляться найденная статья. Для заголовка устанавливаю побольше, чтобы основной поиск вёлся всё-таки по названию статьи.
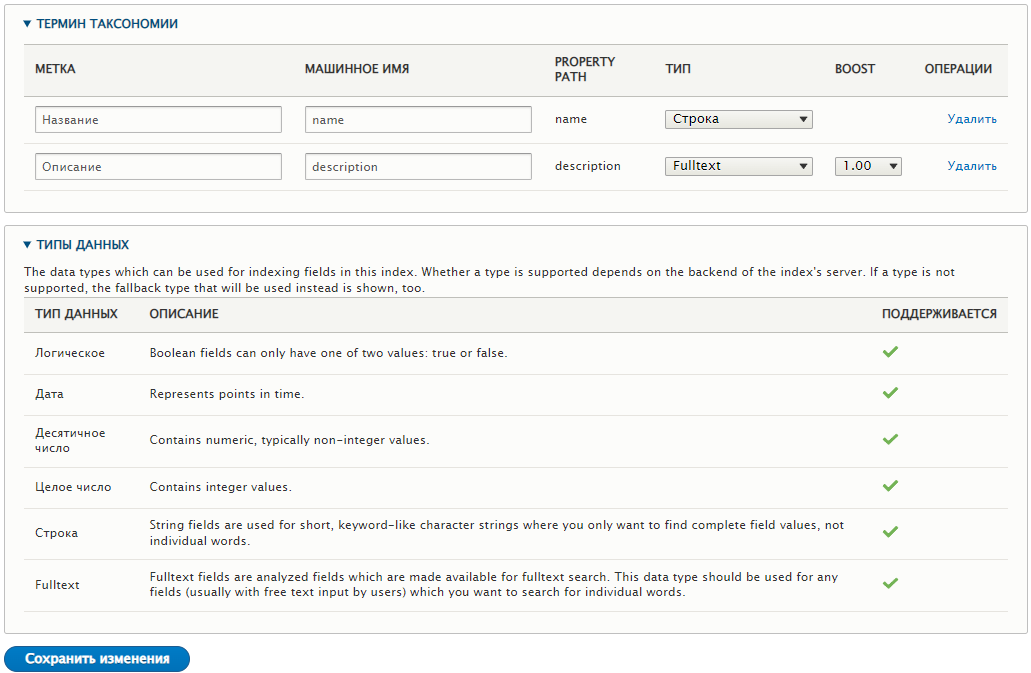
Для полей термина таксономии делаю то же самое. Только для названия указываю строку, здесь не будет применяться морфологический поиск. Сохранить изменения.
Переключаемся на вкладку Процессоры. Ставим галки на нужных нам процессорах. Я включаю:
- Entity status — отбрасывает неопубликованные материалы
- Ignore characters — убирает лишние знаки
- Snowball stemmer — вот это именно то, ради чего мы патчи накатывали, наша морфология
- Tokenizer — символы-разделители слов, точка, дефис (кстати, дефис можно и убрать), символ подчёркивания
- Доступ к материалу — отбрасывает материал, к которому нет доступа
- Игнорировать регистр — собственно, игнорировать регистр
- Подсвеченный — включу подсветку в результатах поиска
- Фильтр HTML — убирает HTML код
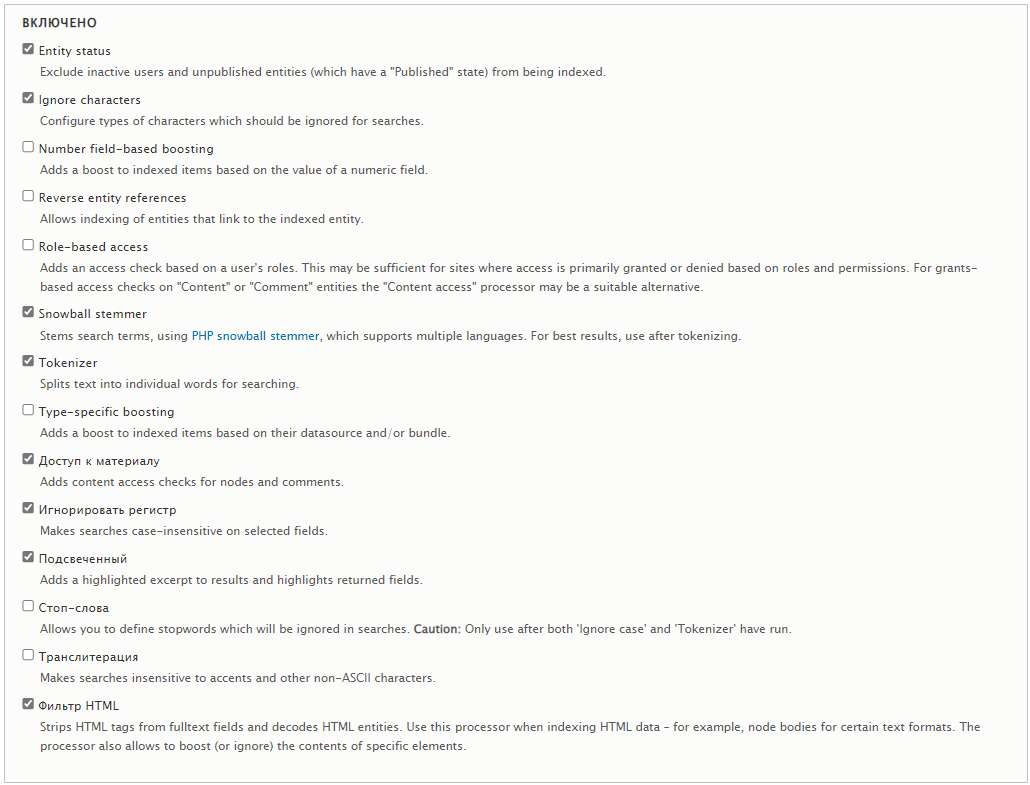
Выбранные процессоры отображаются ниже. Они бывают трёх типов, типы ставятся автоматически:
- PREPROCESS INDEX — срабатывают до выбора данных для индексирования.
- PREPROCESS QUERY — срабатывают в момент запроса
- POSTPROCESS QUERY — срабатывают после получения результатов до их отображения
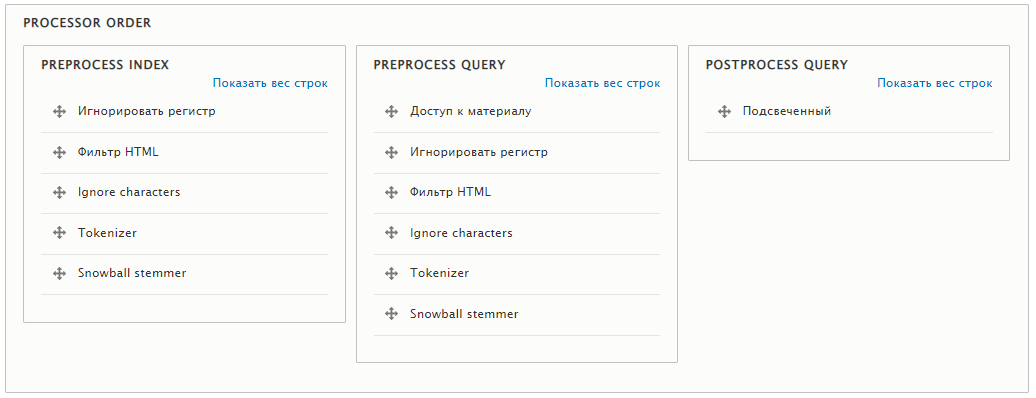
Нам нужно установить порядок выполнения процессоров (сверху вниз). К примеру, имеет смысл использовать HTML до того, как сработает игнорирование символов. Иначе код "Вася Коля Маша" попадёт в индекс как "вася коля маша", потому что игнорирование символа уберёт точки с запятой и фильтр HTML не сможет распознать спецсимволы. Если HTML фильтр первый, получится верное "вася коля маша". Snowball stemmer ставим в самый конец.
После настройки порядка выполнения процессоров можно более точно настроить каждый процессор.
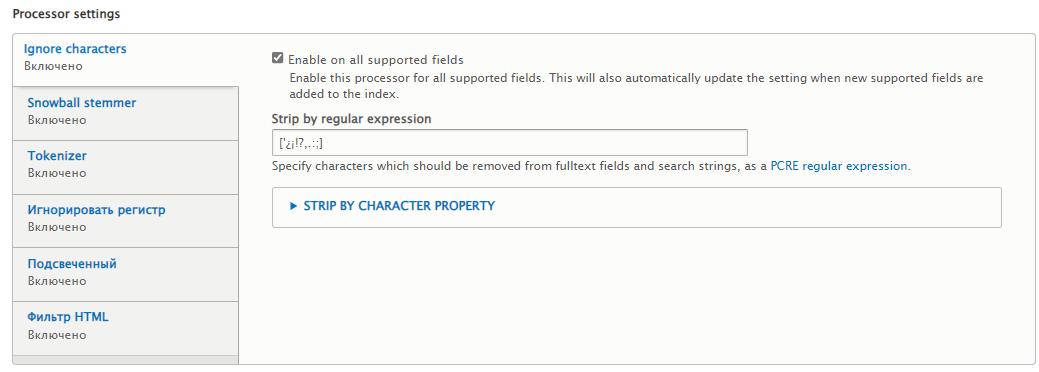
Ignore characters — применяю для всех поддерживаемых полей по указанному регулярному выражения.
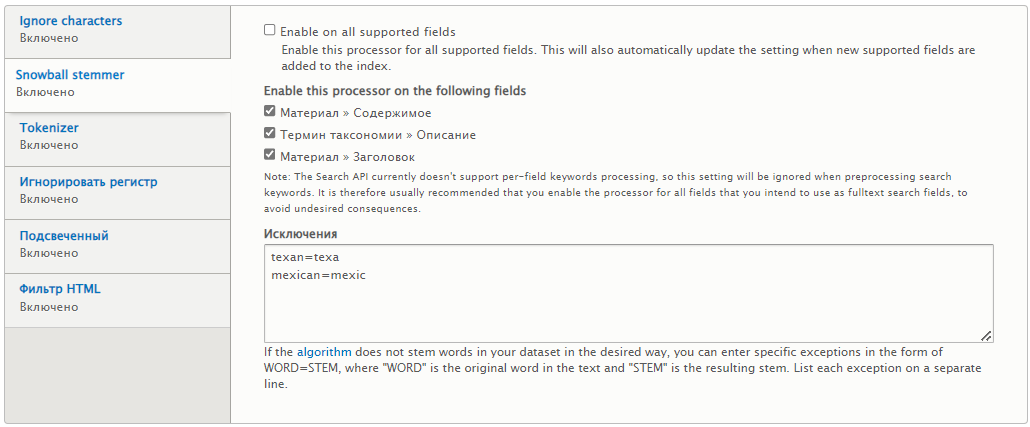
Snowball stemmer — указываю галками конкретные поля, к которым применять морфологический поиск. Для названия термина таксономии процессор не применяется, потому как поле не полнотекстовое.

Tokenizer — применяю для всех поддерживаемых полей. Точка, подчёркивание и дефис. Над дефисом я всё ещё сомневаюсь.
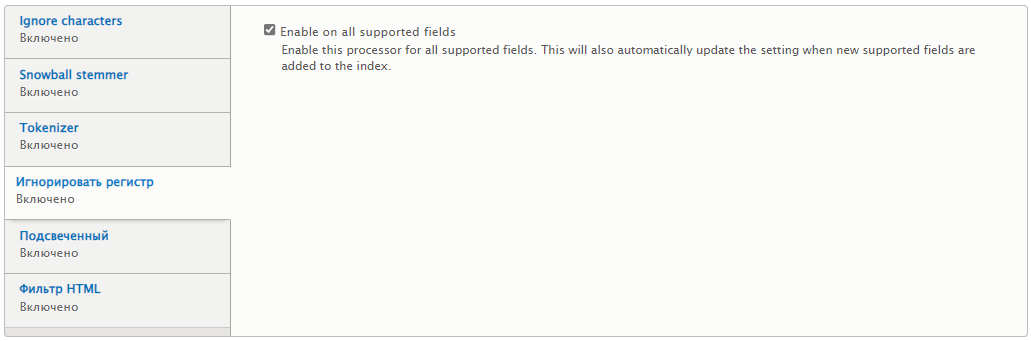
Игнорировать регистр — применяю для всех поддерживаемых полей.

Подсвеченный — применяю для всех поддерживаемых полей. Здесь много разных настроек. Исключаю из подписи заголовок, не нужно его дублировать. Указываю теги, в которые обернуть подсвеченные слова, с моими стилями шаблона подсветка должна быть оранжевой. Указываю длину текста с подсветкой. Вывожу текст даже если подсвечивать нечего.
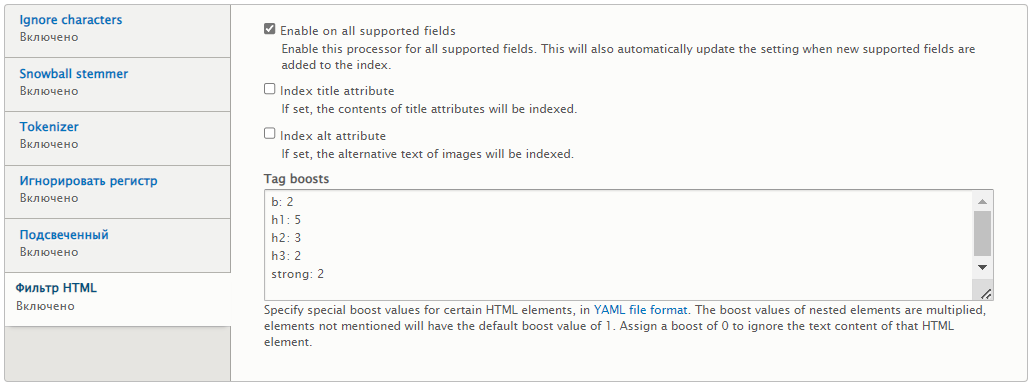
Фильтр HTML — применяю для всех поддерживаемых полей. Здесь можно добавить буст для определённых тегов. Сохранить. Индекс сохранён.
Нажимаем на вкладку Просмотр.
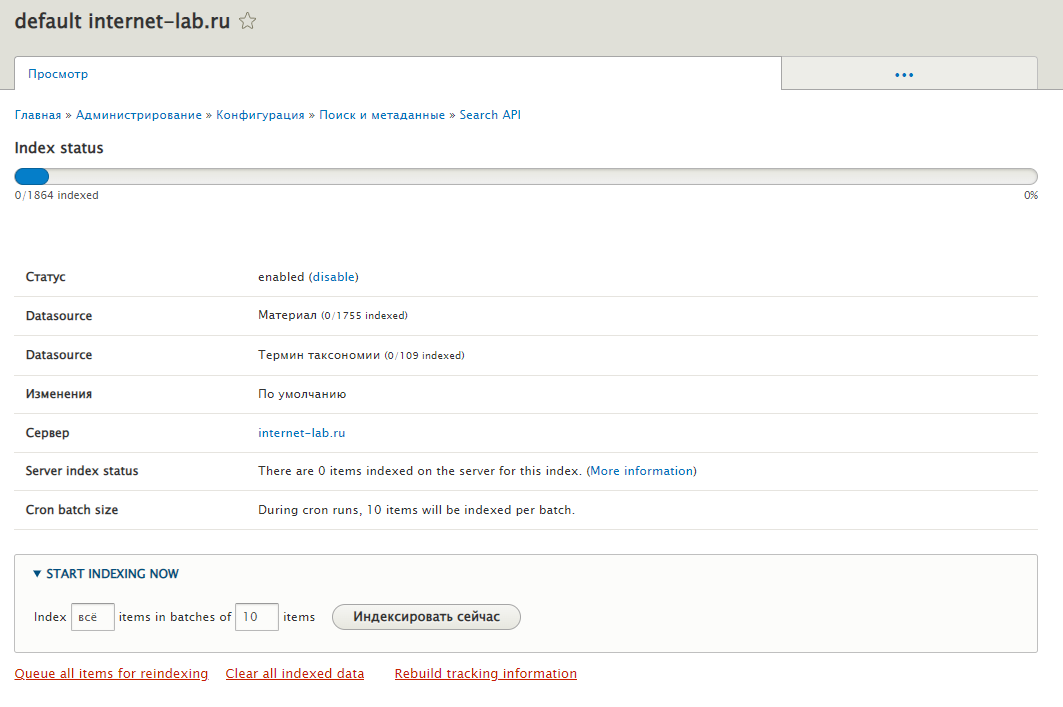
Нажимаем по порядку на ссылки:
- Clear all indexed data
- Queue all items for reindexing
- Rebuild tracking information
Нажимаем на кнопку Индексировать сейчас.

Начинается процесс индексации. Можно попить чай. После окончания индексирования проверяем таблицу search_api_db_название_нашего_индекса. В ней должны быть слова без окончаний.
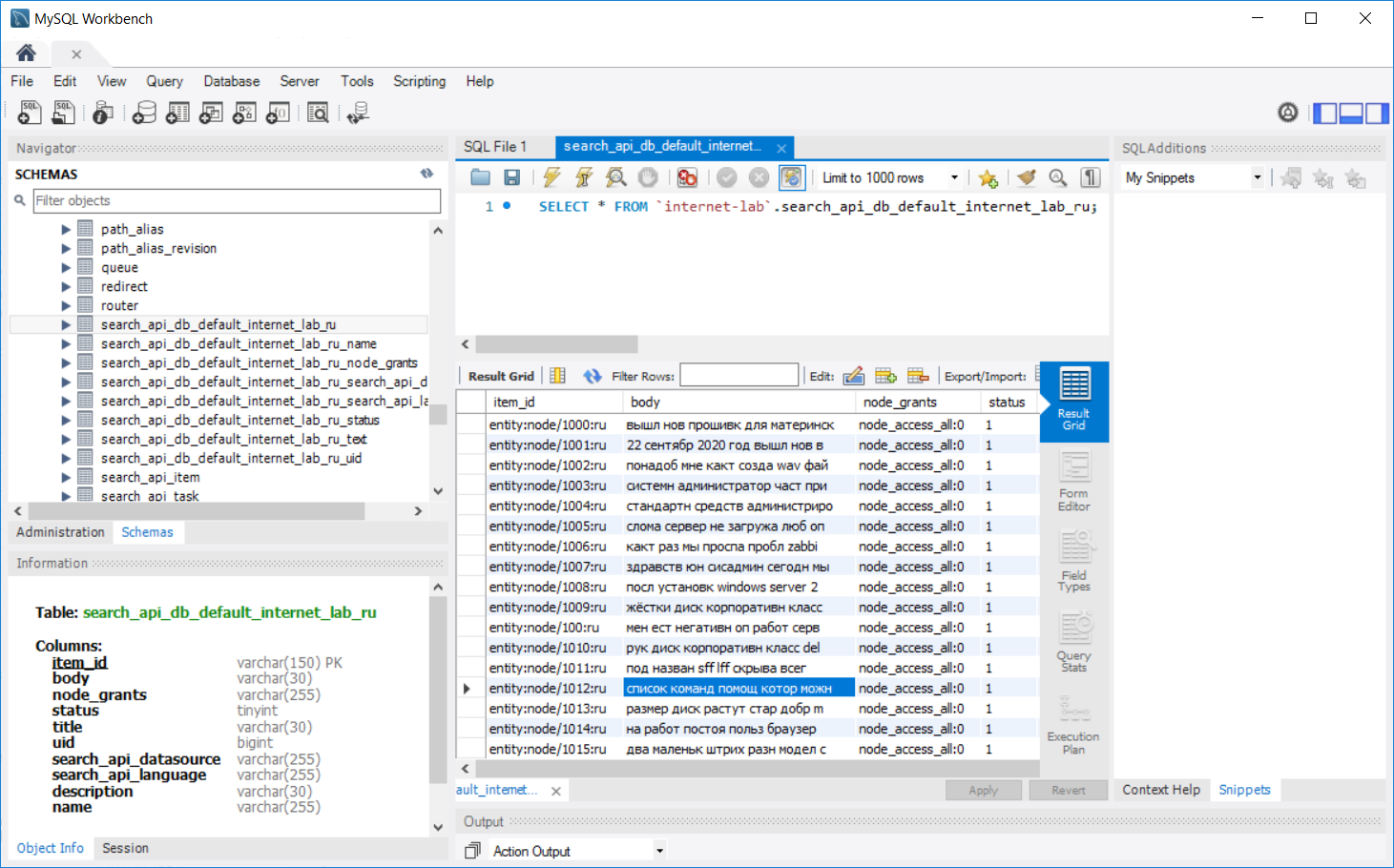
Всё нормально, морфология работает.
Views
Теперь надо настроить страничку поиска. Кто не хочет возиться, переходим дальше к установке модуля Search API Pages. Я только начал разбираться с настройкой поиска через Views, потом забил и использовал Search API Pages. Но первый вариант накатал, вдруг, кому-то пригодится.
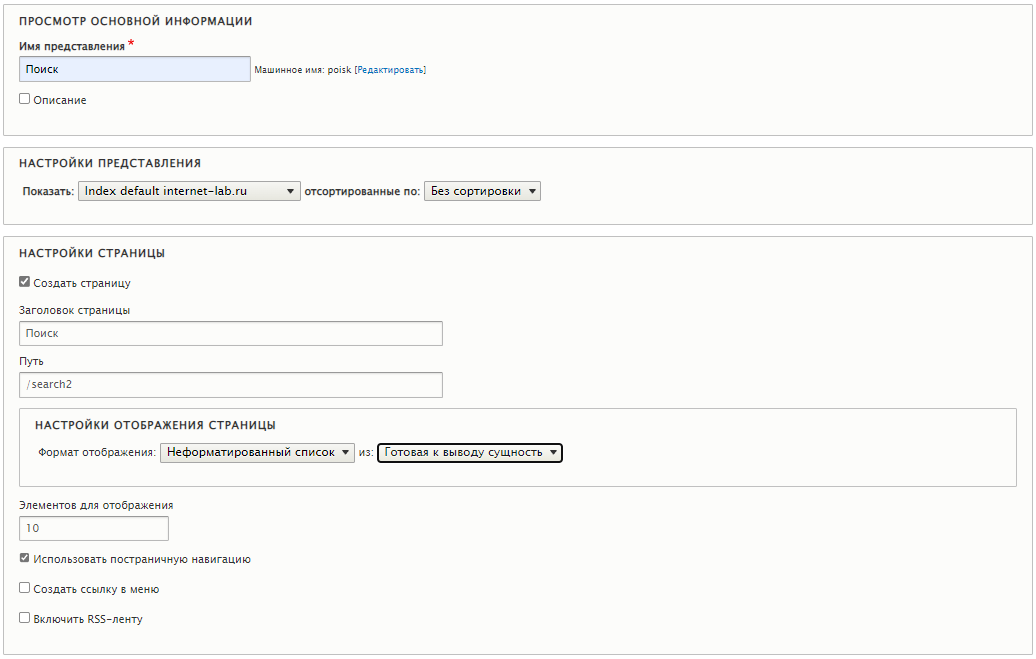
Создаём представление. В настройках выбираем наш индекс. Отображаем готовую к выводу сущность. Путь я пока прописал как "/search2", для тестирования.
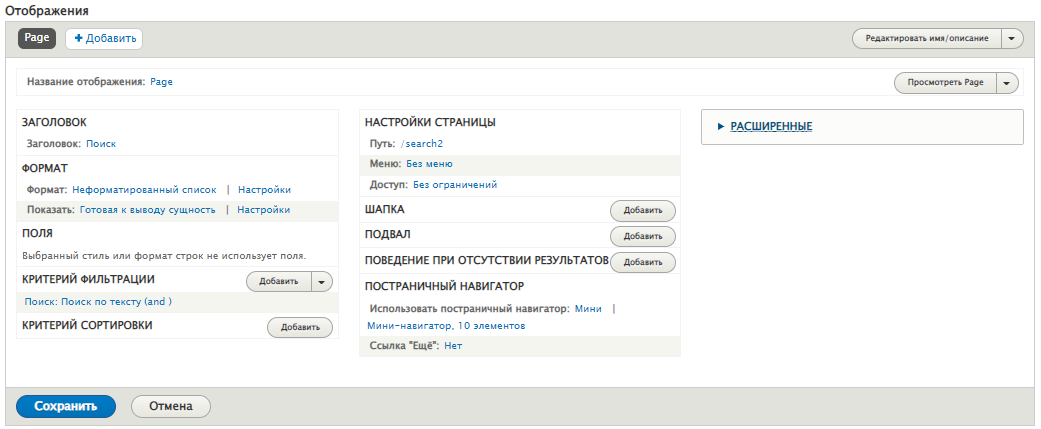
Добавляем фитльтр. Одиночный, раскрытый. Оператор Contains all of these words (AND).
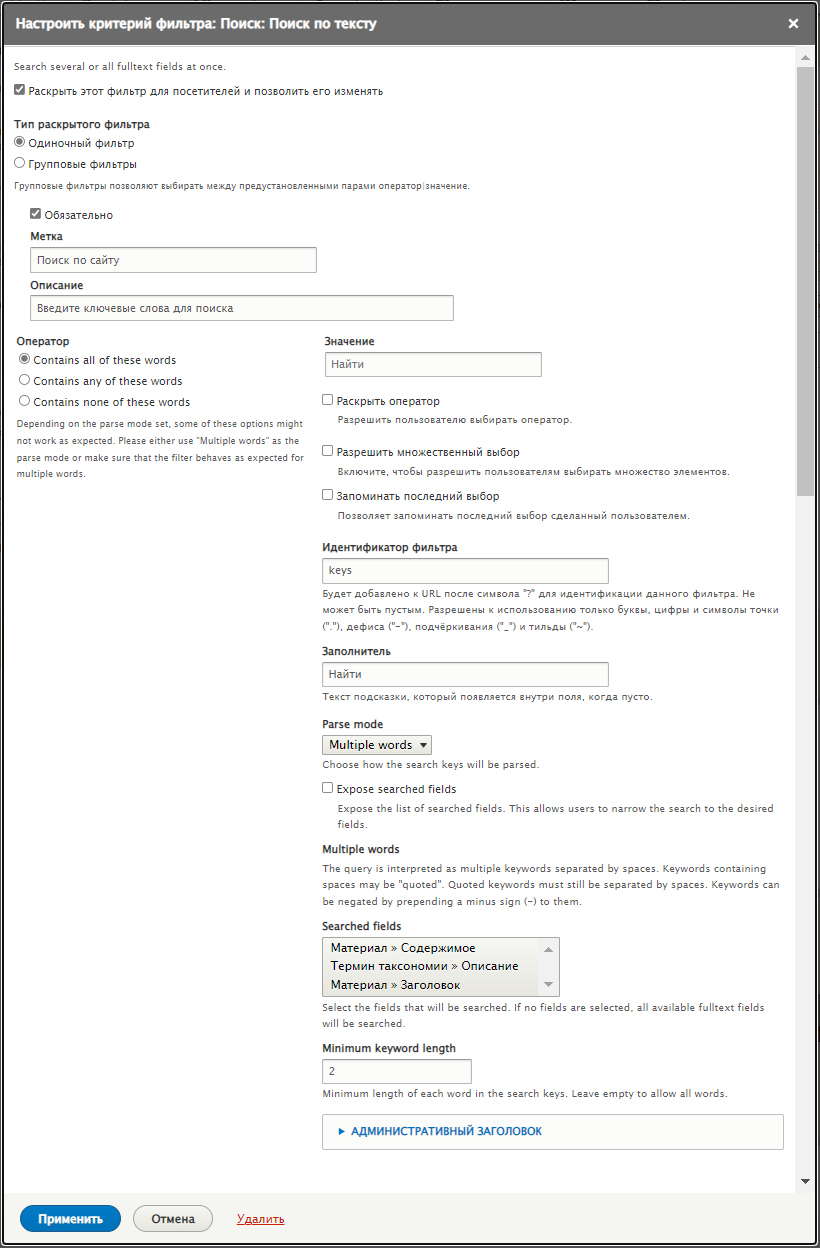
Сохраняем и проверяем что получается.
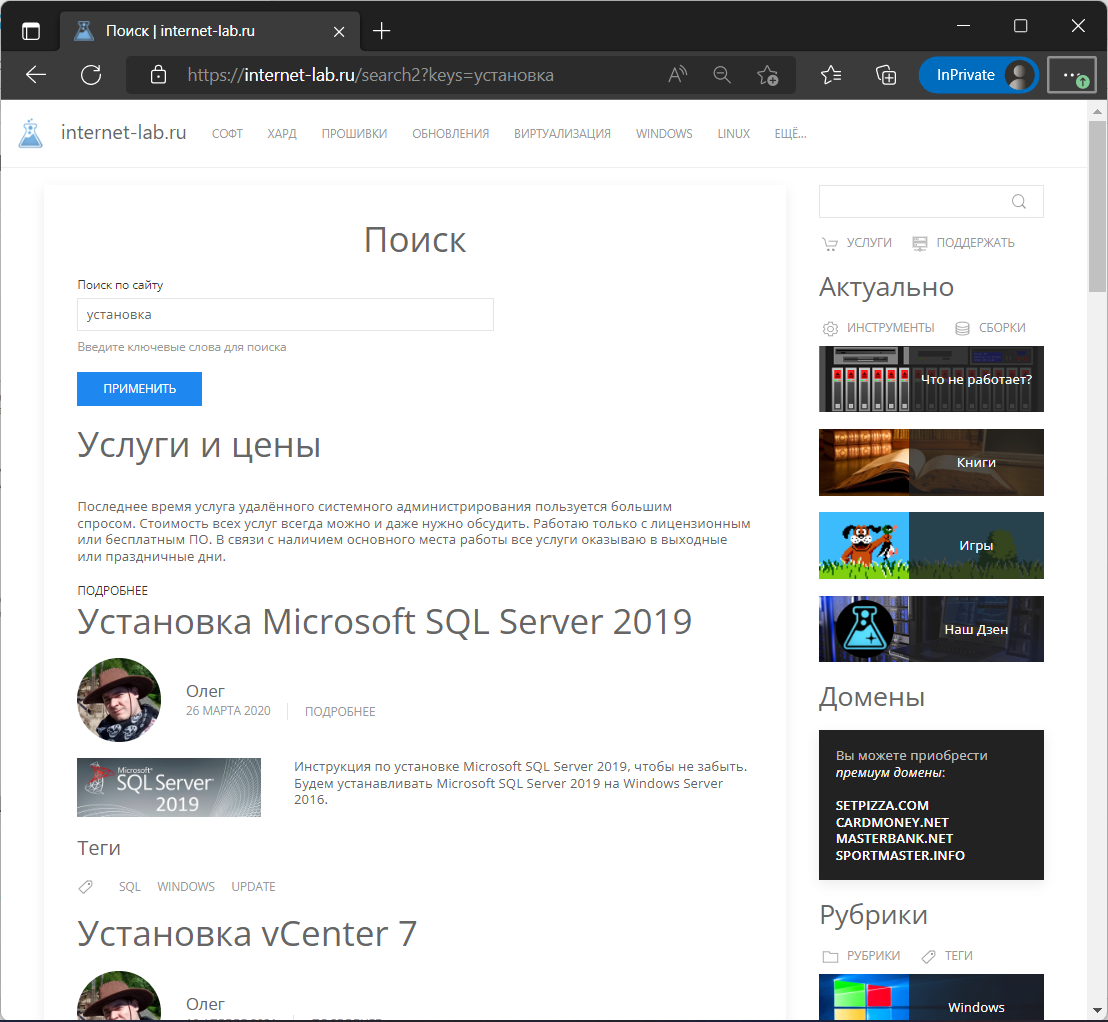
Вроде даже и неплохо вывелось, в виде тизеров. А потом я захотел вывод как в поисковиках, и со всякими красивостями. А ещё блок для поиска делать. И я решил поставить Search API Pages.
Search API Pages
Данный модуль даёт возможность создавать странички поиска для Search API и блоки к ним.
Устанавливаем модуль Search API Pages. Включаем.
Конфигурация → ПОИСК И МЕТАДАННЫЕ → Search API Pages (/admin/config/search/search-api-pages), здесь добавляем новую страницу поиска.
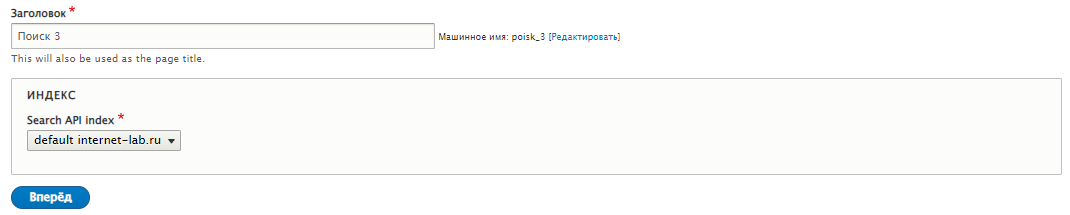
Выбираем наш индекс, указываем название. Вперёд.
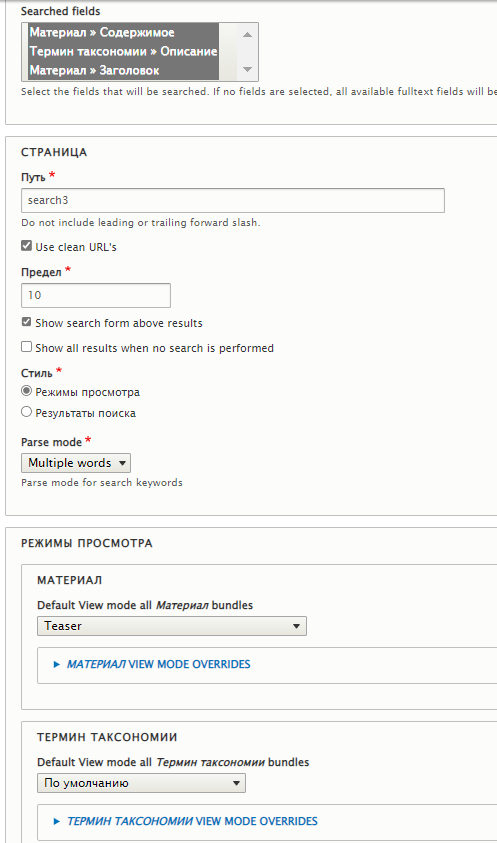
Для начала установлю настройки на вывод результатов в виде тизеров. Примечательна галка Use clean URL's, которая позволяет не использовать параметры в URL. Проверим.
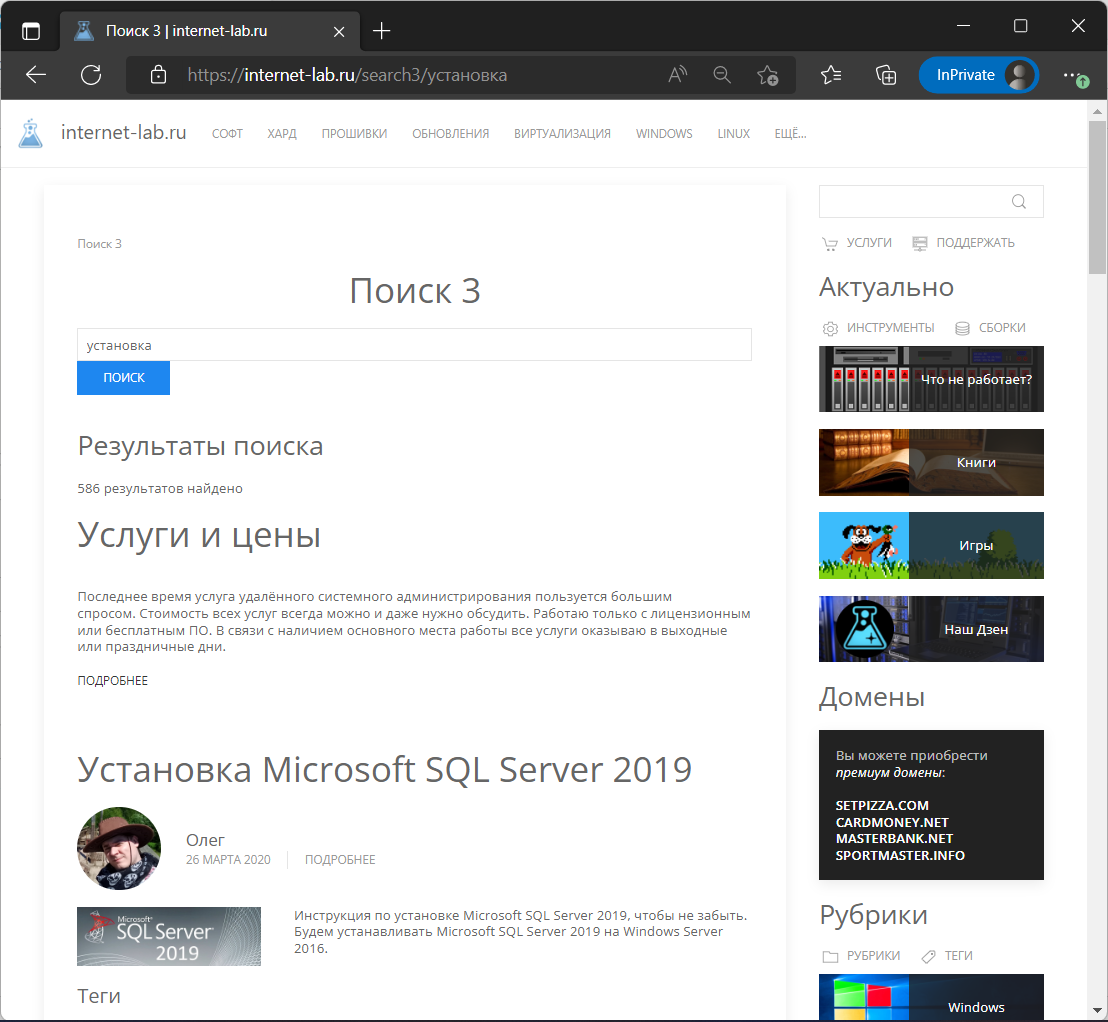
Почти то же самое, что получилось у меня в Views, но отображается количество результатов поиска. И блок создался, можно вынести в правую панель. Играю с параметрами дальше.
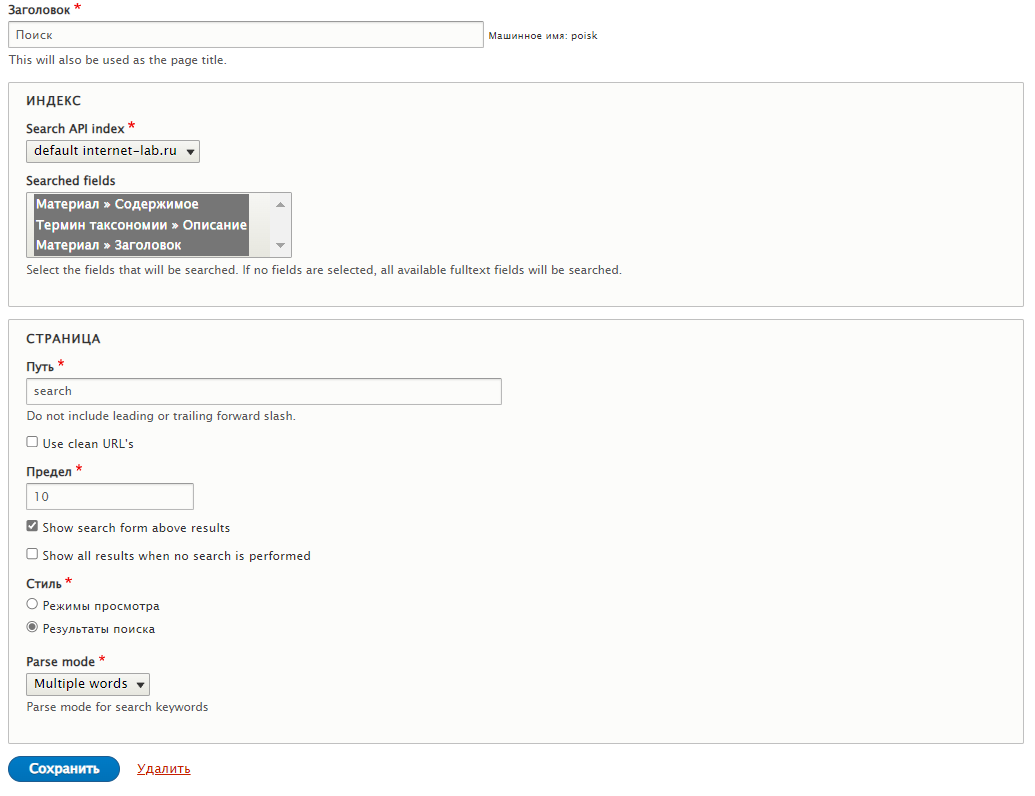
Меняю путь на "/search", устанавливаю стиль "Результаты поиска", чистые URL отключу. Немного шаманю с шаблонами, чтобы сделать красивее форму. Проверим.
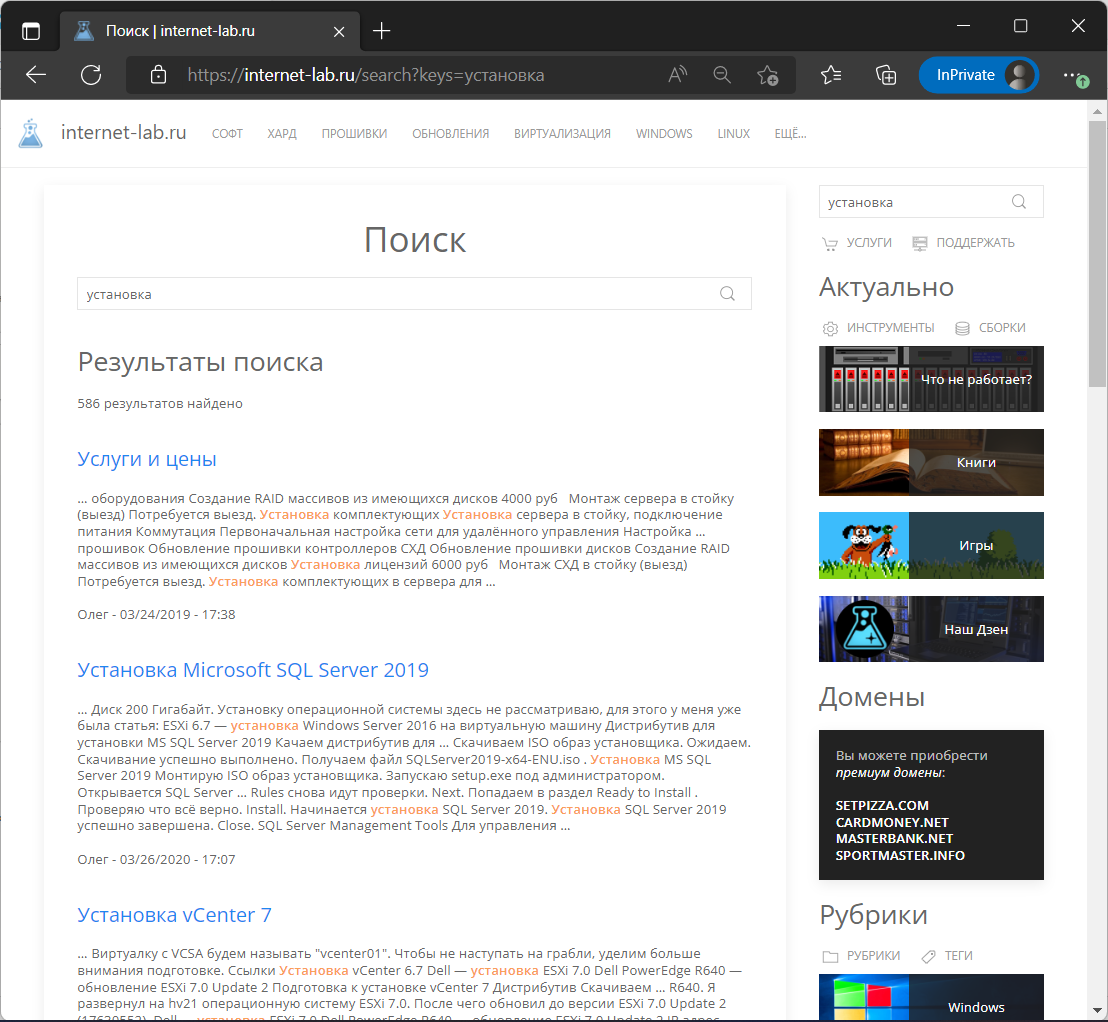
Вот это я и хотел! На самом деле всё это можно сделать и через Views, только нужно возиться, а мне не хочется. Но если хочется заняться творчеством, то вы можете использовать представления.
Заключение
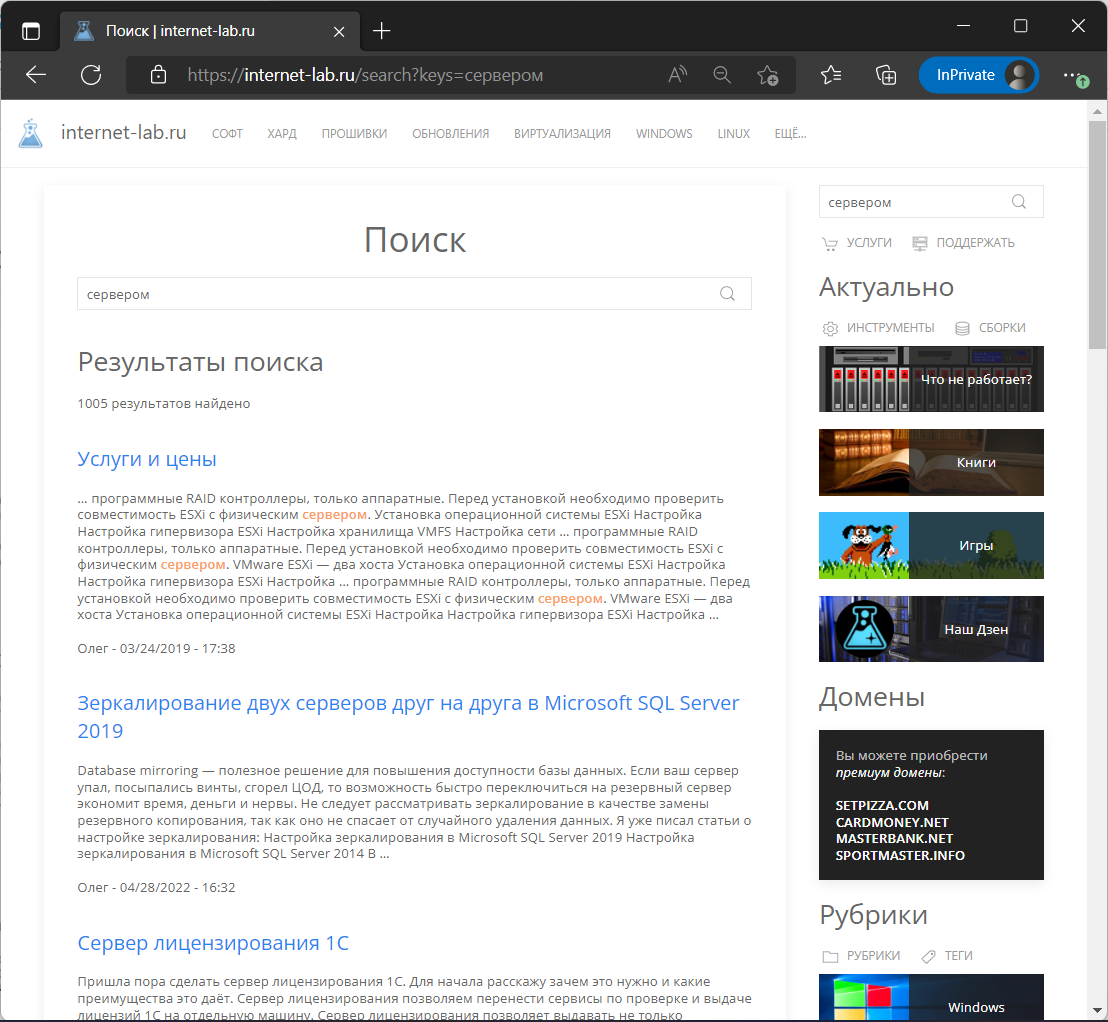
Мы с вами в Drupal заменили обычный поиск модулем Search API. Дополнительно прикрутили модуль Snowball Stemmer для морфологического поиска. Теперь результаты поиска соответствуют морфологическим словоформам запроса. Например, на запрос "сервером" вывелась статья про зеркалирование серверов, хотя в ней нет именно такого слова.
В процессе работы нам пришлось накатить два патча, подружиться с модулем Ludwig, который может иногда заменить Composer, попробовать свои силы в создании представлений и освоить Search API Pages.
Ссылки
Немного ссылок на статьи, которые мне помогли во всём разобраться. Начал я отсюда:
Drupal: Search API и поиск с морфологией | xandeadx.ru
Модули:
Патчи:
- https://www.drupal.org/files/issues/2021-03-23/3205094-02.patch
- https://www.drupal.org/files/issues/2022-04-08/search-api-processor-langauges-support-3274194-3.patch
Примечание
После обновления Snowball Stemmer пришлось его удалять, потом заново ставить по этой инструкции, иначе зависимости Ludwig выводились с ошибкой.





















