


Похоже, одна поездка в ЦОД резко превратилась в несколько. И дополнительно подкинула проблем... HP ProLiant DL360 Gen9 выдал ошибку:
EVENT (29 Sep 14:00): Uncorrectable Machine Check Exception (Board 0, Processor 2, APIC ID 0x00000020, Bank 0x00000007, Status 0xB2000000'0200008F, Address 0x00000000'00000000, Misc 0x0000A000'40280000)
Не успел я понять в чём проблема, как сразу пришло второе сообщение:
EVENT (29 Sep 14:00): POST Error: 295-DIMM Failure - Uncorrectable Memory Error - Processor 2, DIMM 10. This memory will not be available to the operating system. ACTION: Replace the failed DIMM to restore the full amount of memory.
Вот оно в чём дело. Итак, по порядку.
Жил был у меня сервер HP ProLiant DL360 Gen9, в который было воткнуто 16 планок DIMM по 16 ГБ каждая. И вот памяти стало не хватать. Докупили ещё 8 планок, благо слоты свободные были. Сервер забит под завязку.

При включении сервер показал 384 ГБ ОЗУ. Всё точно. 16 * 24 = 384.
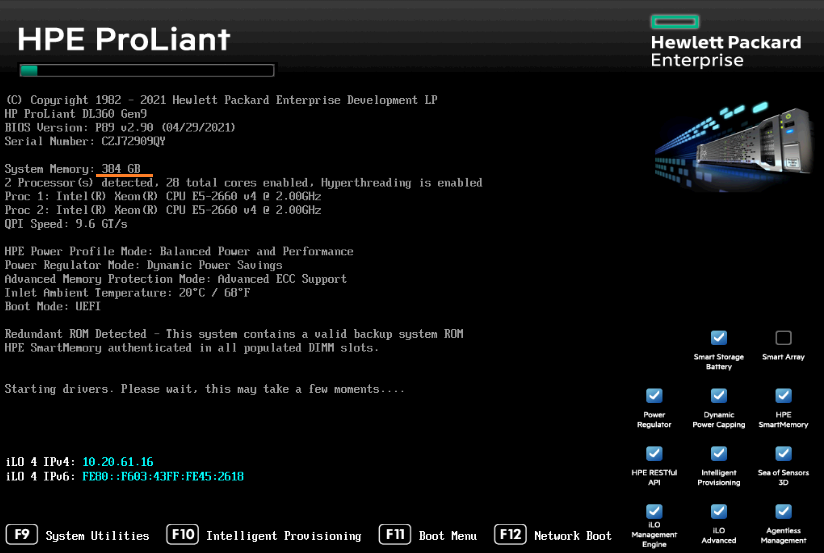
На сервере крутится гипервизор ESXi 7. Пару дней сервер постоял без нагрузки, сегодня я решил ввести его в бой. Включил виртуальные машины и вдруг...
RAID контроллер выплёвывает ошибку, сервер уходит в перезагрузку, виртуальные машины останавливаются. После перезагрузки получаю указанные в начале поста ошибки. И вот это:
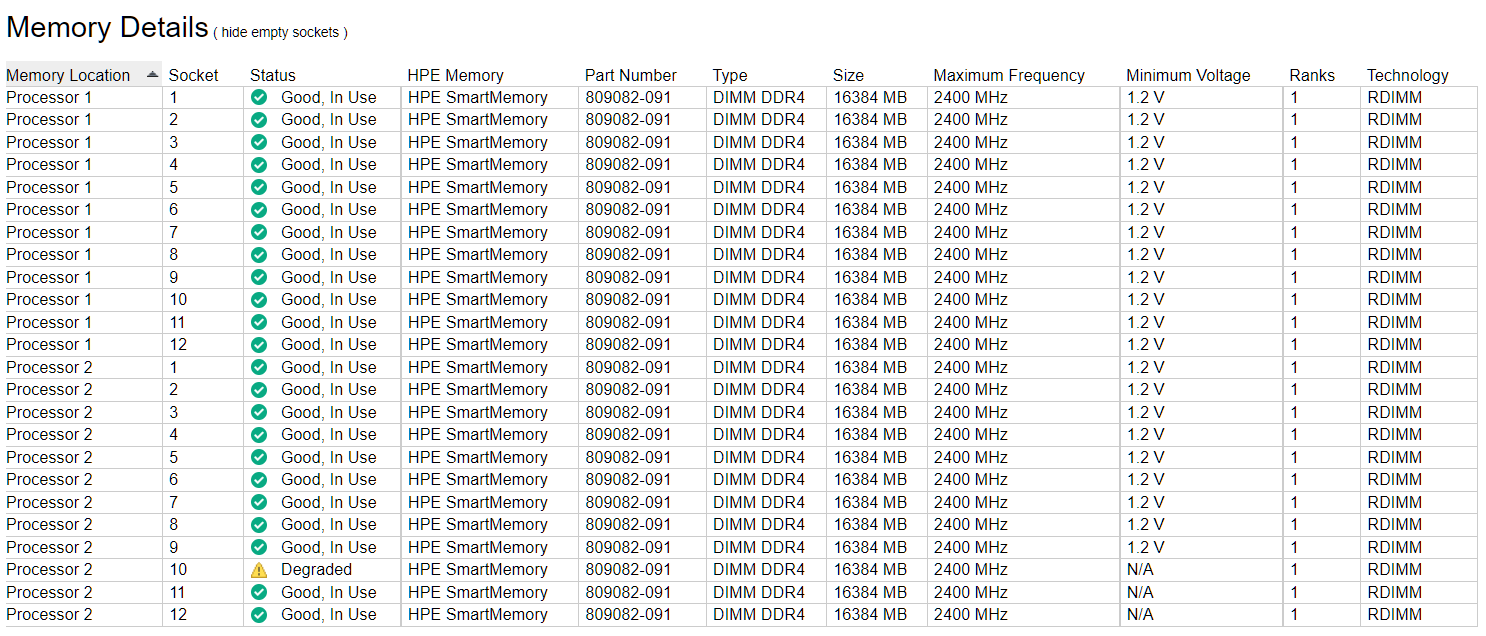
В десятом слоте память Degraded, а в 11 и 12 слоте не отображается вольтаж. Я сразу на это внимания не обратил, а зря. Запускаю встроенную диагностику памяти.

Мгновенная проверка памяти: УДАЧНО. Проверено 335 Гб. Стоп, почему 335?
16 * 24 = 384 384 - 335 = 49 49 / 16 ≈ 3
Три планки памяти не участвуют в проверке. Как я понимаю, это сбойная 10-я, 11-я и 12-я до кучи. Получается, сервер отключил всю память после сбойной. И на самом деле неясно, одна битая или две. Или три. Это, конечно, маловероятно, потому как порядок установки памяти такой, что 11-й и 12-й слоты используются раньше чем 10-й.
Завтра еду менять память.




















