


vNUMA
В VMware 7 есть технология виртуальных узлов NUMA — vNUMA. Эта технология по умолчанию начинает работать при соблюдении одного из условий:
- Количество процессоров виртуальной машины vCPU превышает количество ядер одного физического NUMA-узла.
- Количество процессоров виртуальной машины vCPU больше 8.
Поведение vNUMA можно изменять с помощью Advanced Settings виртуальной машины. Это может понадобиться в нескольких случаях:
- Лицензия операционной системы или приложения не позволяет иметь более определённого количества физических процессоров или узлов NUMA.
- Производительность софта зависит от узлов NUMA.
К примеру, есть мнение, что для работы 1С лучше использовать один узел NUMA, если физический процессор это позволяет.
UMA и NUMA
В типовых многопроцессорных архитектурах доступ процессоров к памяти организован в архитектуре UMA, известной также как SMP. В этой архитектуре процессоры соединены с общей памятью при помощи шины симметрично, и имеют к ней равный однородный доступ.
UMA (Uniform Memory Architecture) — архитектура однородного доступа к памяти.
SMP (Symmetric Multi Processing) — симметричная многопроцессорная обработка.
Все процессоры обращаются к контроллеру памяти (MCH/MGCH), который нам известен как "Северный мост". Недостаток UMA сразу бросается в глаза — при росте числа CPU шина становится узким местом и ограничивает производительность приложений, использующих память. Мы упираемся в предел количества процессоров, три десятка CPU и всё. "Сгорел северный мост" — это наш случай.
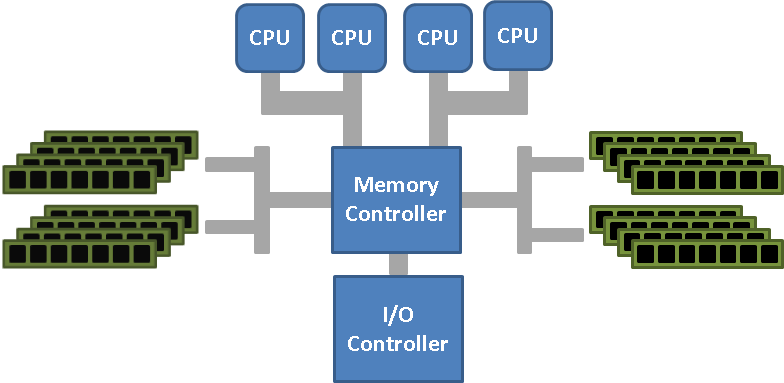
От узких мест следует избавляться. И тогда контроллер памяти убрали и встроили в каждый процессор. И каждому процессору выделили свой блок сокетов памяти. Если какому-то процессору памяти не хватало, то он просил поделиться соседа. Такую архитектуру неоднородного доступа к памяти назвали NUMA.
NUMA (Non-Uniform Memory Architecture) — архитектура неоднородного доступа к памяти.
Преимущества очевидны, мы избавились от узкого места и ликвидировали северный мост. Но есть и недостатки, если процессору не хватает своей памяти, то ему приходится обращаться к соседней памяти не напрямую, а через посредника. Как реализовано в AMD Hyper-Transport (HT):
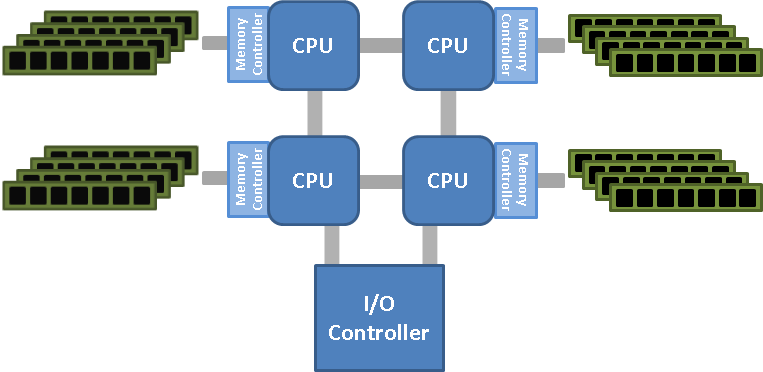
А если даже памяти двух процессоров не хватает, то требуется привлечь память ещё одного процессора, цепочка растёт. Технологии не стоят на месте, процессоры усложняют и делают промежуточные соединения. Как реализовано в Intel Quick-Path (QPI):
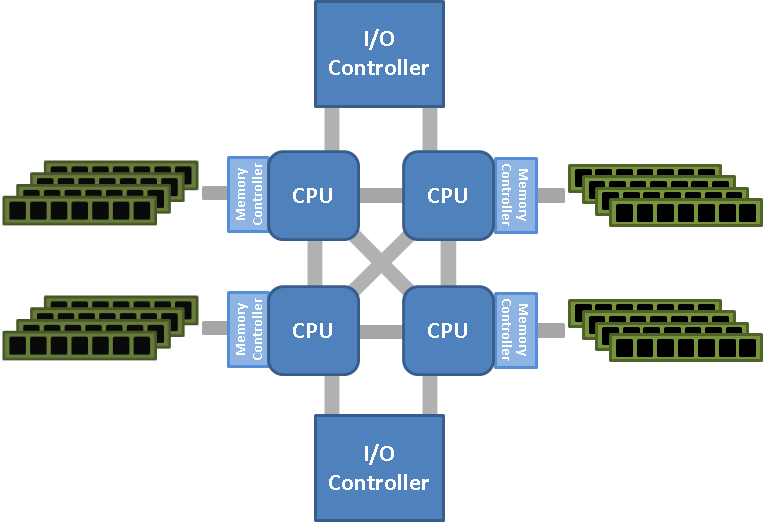
Но это уже частности. В общем случае узлом NUMA называют блок процессора с доступной ему напрямую памятью.
Рулим vNUMA
Давайте рассмотрим конкретный пример. В итоге получим виртуальную машину с 1 сокетом, 20 логическими CPU и одним узлом NUMA.
Есть двухпроцессорный гипервизор ESXi 7:
- Количество процессоров: 2
- Тип процессоров: Intel Xeon Gold 5218 CPU @ 2.30GHz
- Логических процессоров: 64
- Память: 256 ГБ
Физически у нас два узла NUMA, каждый из которых имеет 32 логических процессора (с гипертрейдингом), в каждом узле 128 ГБ ОЗУ.
Создадим виртуальную машину с 4 CPU на борту и 40 ГБ оперативной памяти. Данные ресурсы помещаются в один узел NUMA. При выборе количества процессоров можно указать количество ядер на сокет. По умолчанию создаётся одно ядро на сокет, получится четыре виртуальных сокета с одним ядром на сокет.
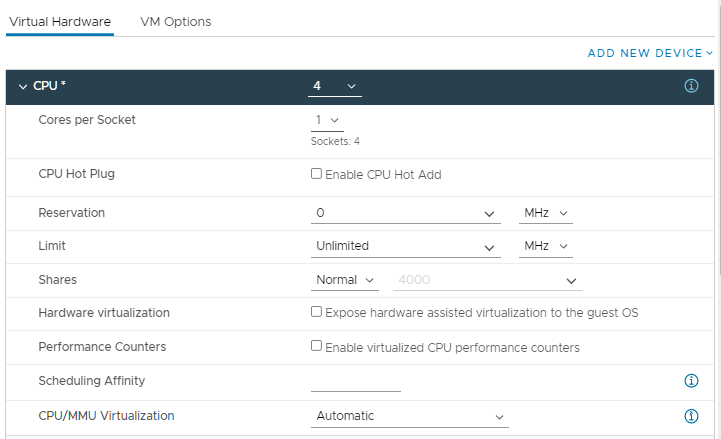
Запускаем Windows и смотрим что получилось. В диспетчере задач переключаемся на вкладку Performance, выбираем CPU. Нажимаем правой кнопкой на график, и выбираем режим NUMA nodes. Данный режим даже включиться не может, потому что узел NUMA один. Четыре сокета по одному ядру, всё как настраивали.
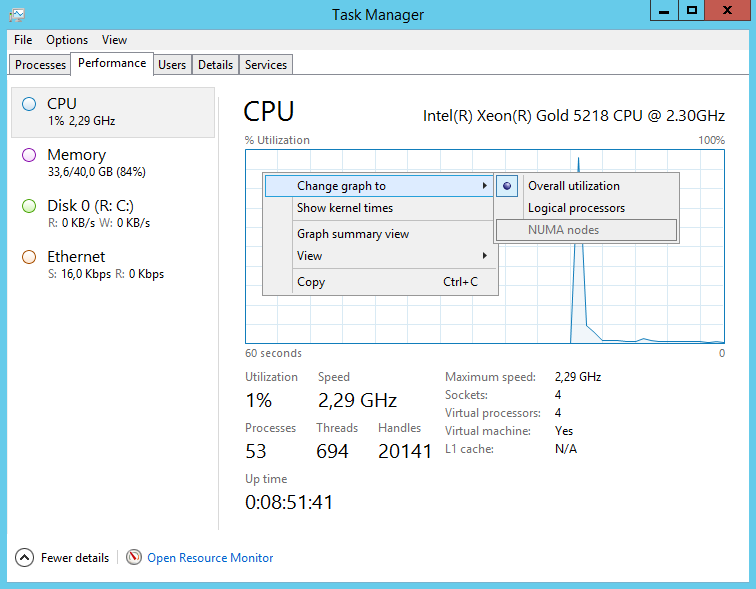
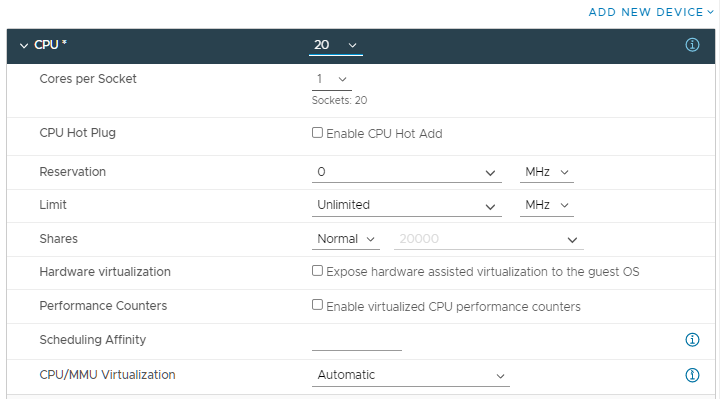
Выключаем сервер и доводим количество процессоров до 20.
Запускаем Windows и смотрим что получилось. В диспетчере задач переключаемся на вкладку Performance, выбираем CPU. Нажимаем правой кнопкой на график, и выбираем режим NUMA nodes. Данный режим теперь доступен, графиков становится два. Автоматически сработала технология виртуальных узлов vNUMA, у нас теперь два узла NUMA. Двадцать сокетов по одному ядру.
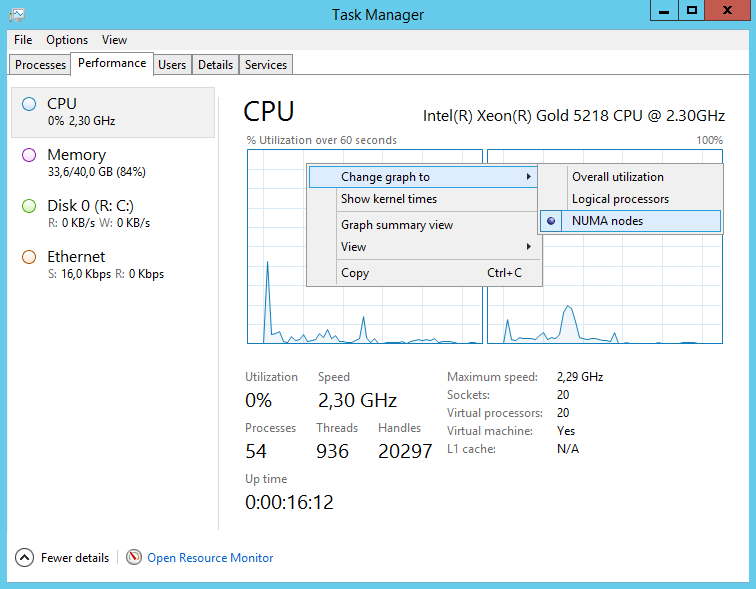
Нагрузка на оба физических процессора стала равномерной, но что делать, если нам требуется только один узел NUMA? Настроим. Выключаем сервер. В свойствах виртуальной машины переходим во вкладку VM Options.
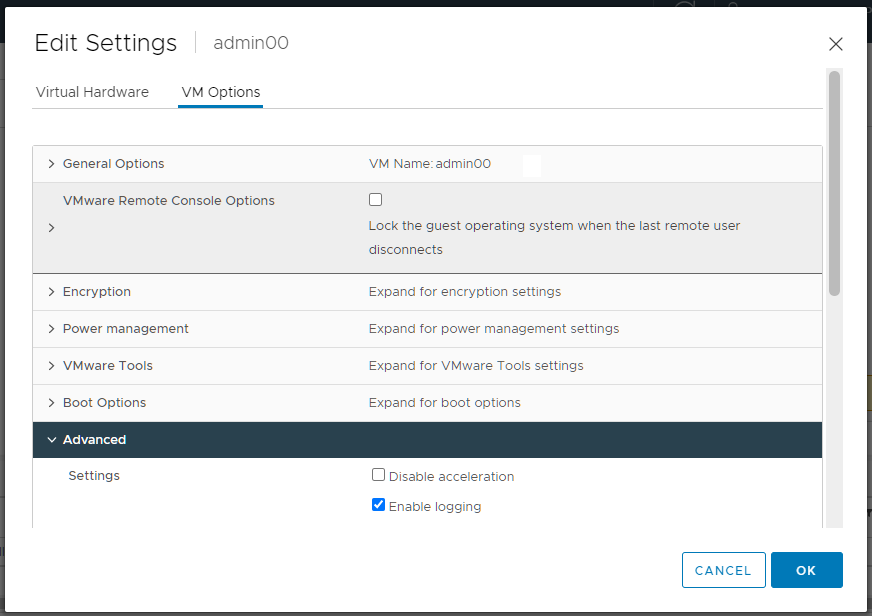
Advanced → EDIT CONFIGURATION.
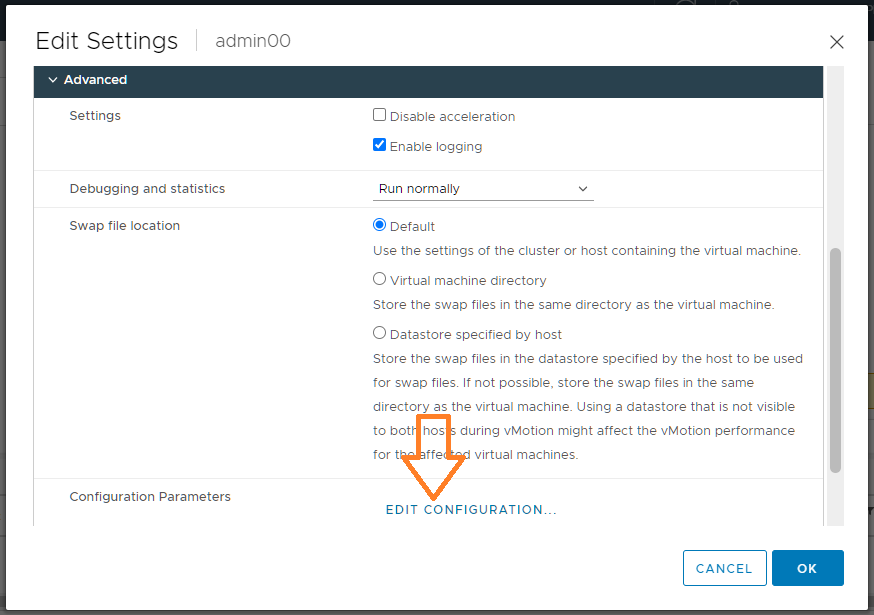
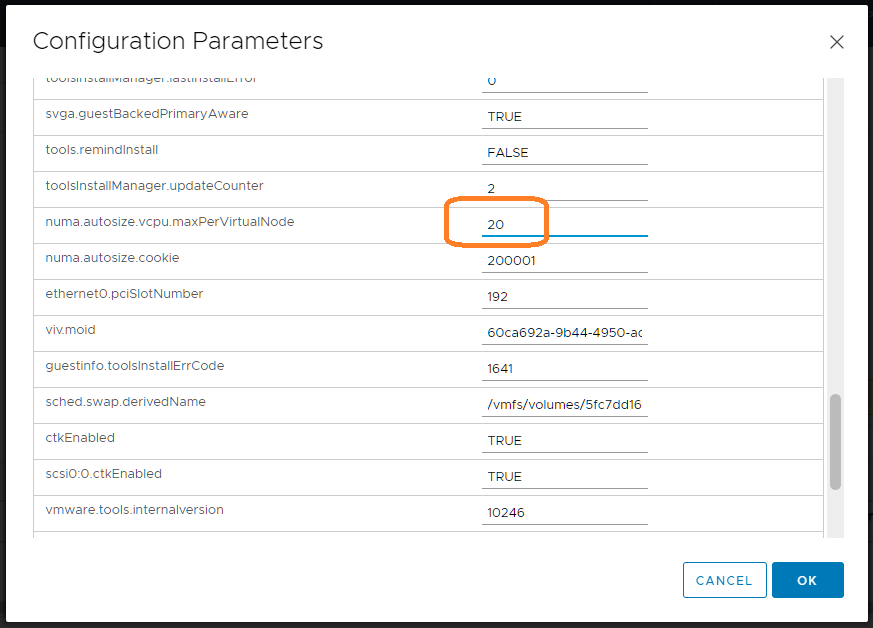
Находим параметр "numa.autosize.vcpu.maxPerVirtualNode". Параметр определяет количество виртуальных узлов NUMA путем деления общего количества виртуальных CPU на равные части с этим значением в качестве делителя. По умолчанию значение 8, т.е. на каждые 8 процессоров создаётся узел NUMA. Меняем его значение на текущее количество процессоров, в нашем случае на 20.
numa.autosize.vcpu.maxPerVirtualNode = 20
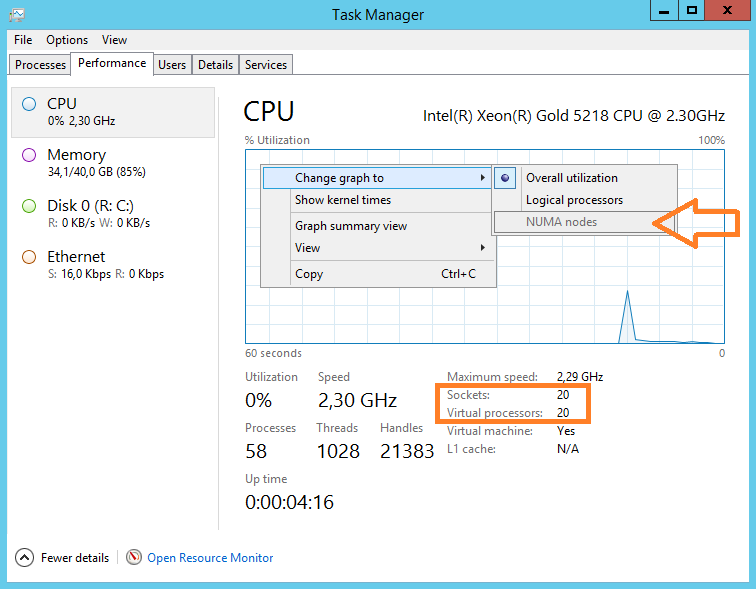
OK. Запускаем Windows и смотрим что получилось. В диспетчере задач переключаемся на вкладку Performance, выбираем CPU. Нажимаем правой кнопкой на график, и выбираем режим NUMA nodes. Данный режим включиться не может, потому что узел NUMA теперь один. Двадцать сокетов по одному ядру.
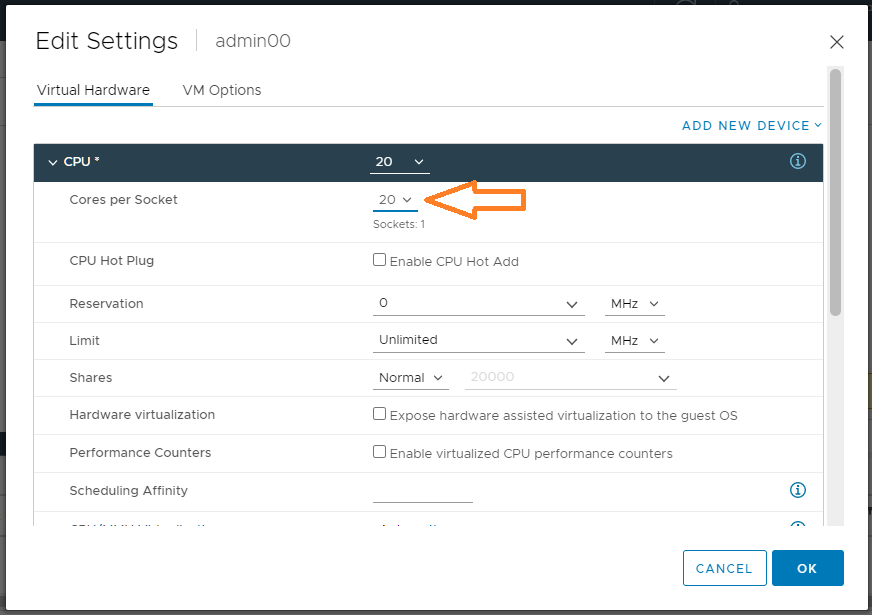
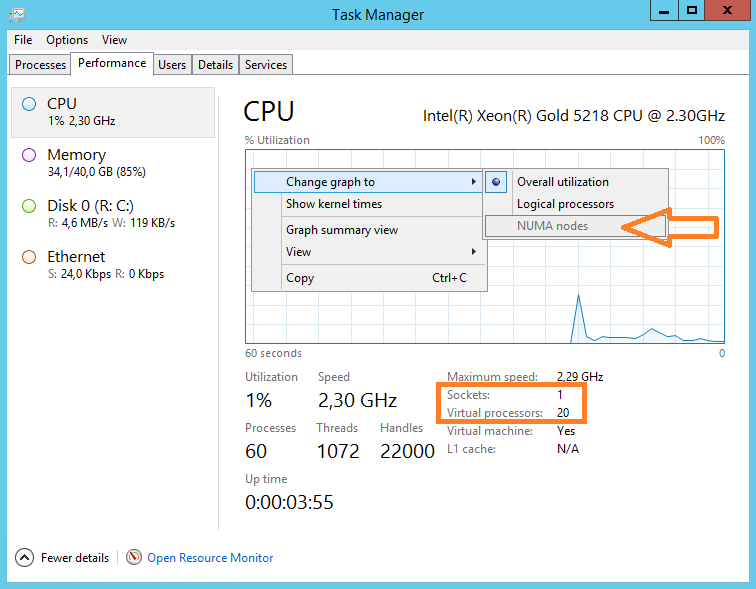
Почти то что планировали, с NUMA разобрались, только сокетов многовато. Выключаем сервер. В настройках виртуальной машины правим параметр Cores per Socket. Устанавливаем значение 20. У нас в каждом сокете будет 20 логических процессоров. Т.е. получим один сокет с 20 логическими CPU.
OK. Запускаем Windows и смотрим что получилось. А получилось у нас то, что мы и планировали. NUMA узел: 1, сокет: 1, логических процессоров: 20. Теперь виртуальная машина будет потреблять ресурсы только одного физического процессора.
Вместо заключения
Мы научились управлять узлами NUMA на виртуальной машине VMware 7. Заодно посмотрели как делить логические процессоры по сокетам.
Я не ставил перед собой цель сравнивать производительность виртуальной машины при различных количествах узлов NUMA, в каждом конкретном случае она может отличаться. Но, умея рулить NUMA, вы теперь и сами можете это сделать.




















