


Я уже писал о реанимации отвалившихся дисков NVMe. В первом случае у меня рассыпался namespace:
Вот втором случае namespace остался целым, но диск выпал из устройств PCI:
Реанимация NVMe диска в Linux — 2
Сегодня у нас очень похожий случай, NVMe диск выпал из устройств PCI, из mdadm массива, соответственно тоже. Если раньше реанимация проводилась на RAID1 массивах, то сегодня пострадал RAID10. Возможно, именно из-за этого процедура восстановления оказалась чуть сложнее.
Итак, тестовый стенд представляет собой сервер с операционной системой Oracle Linux. В сервере четыре NVME диска Samsung, которые объединены в зеркальный программный RAID10 массив.
Samsung SSD MZPLJ12THALA-00007 — NVMe 12.8 ТБ
Помимо этого в сервере есть ещё два NVME диска Samsung, которые объединены в зеркальный программный RAID1 массив.
Samsung SSD 3.2TB PCIe MZPLJ3T2HBJR-00007
Один из NVMe дисков в RAID10 массиве на сервере перестал работать. Массив, собранный с помощью mdadm, перешёл в состояние degraded. Сработал мониторинг, начинаем разбираться в ситуации. Сервер перезагружать нельзя, будем чинить прямо так.
Посмотрим состояние массивов:
cat /proc/mdstat
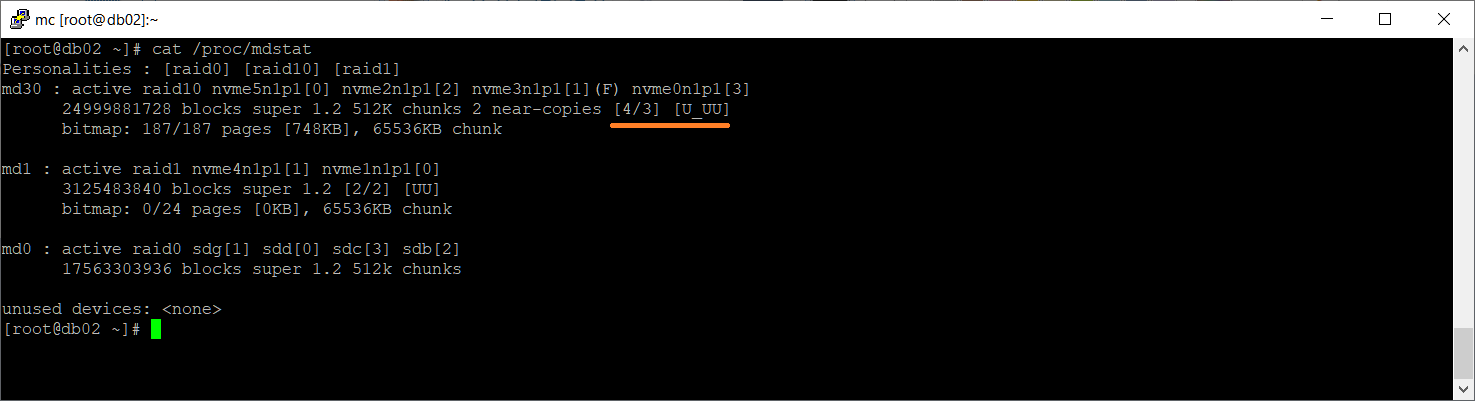
В массиве md30 работают три из четырёх дисков: [U_UU]. В качестве дисков массиву переданы четыре раздела:
- /dev/nvme0n1p1
- /dev/nvme2n1p1
- /dev/nvme3n1p1 (F)
- /dev/nvme5n1p1
По значку (F) видно, что /dev/nvme3n1p1 — faulty. Посмотрим подробности:
mdadm --detail /dev/md30
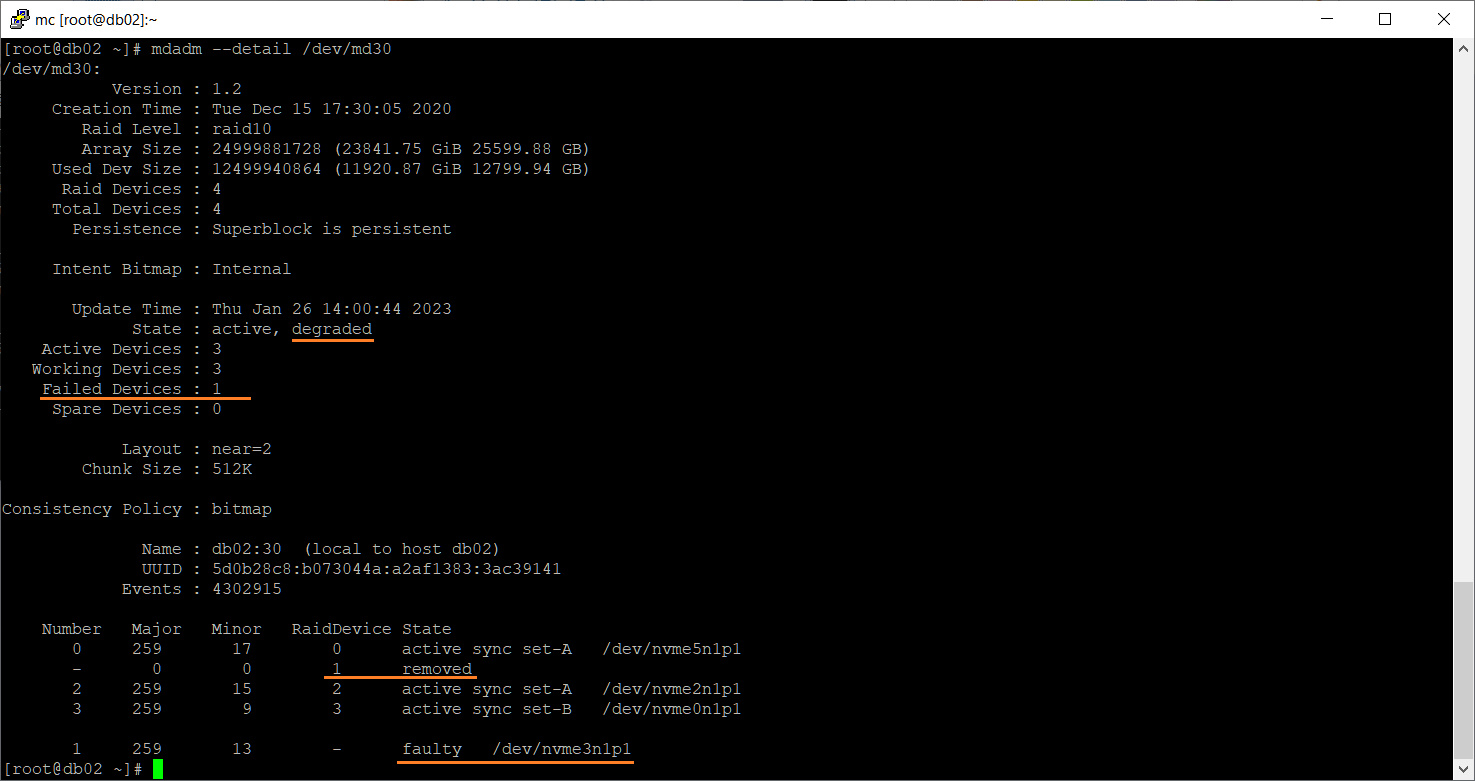
А диск-то у нас из массива не удалился на этот раз. Он числится в массиве и помечен как сбойный.
Посмотреть информацию об NVMe дисках можно с помощью утилиты nvme из пакета nvme-cli:
NVMe Command Line Interface (NVMe-CLI)
yum install nvme-cli
или
apt install nvme-cli
nvme list

Однако, утилита не смогла обнаружить диск /dev/nvme3n1. Видим пять устройств, а должно быть шесть. Можно посмотреть, определяется ли диск как PCI устройство командой lspci.
lspci | grep -E "NVMe|Non-Volatile"
Диски бывают разные, у меня Samsung, можно и по-другому вычислить:
lspci | grep Samsung
04:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824 41:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824 44:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824 47:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824 84:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824 87:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824
В списке присутствуют все шесть NVMe дисков из обоих RAID массивов. Нам нужно определить адрес сбойного диска.
cd /sys/bus/pci/drivers/nvme/
ll
Сравниваем два списка.
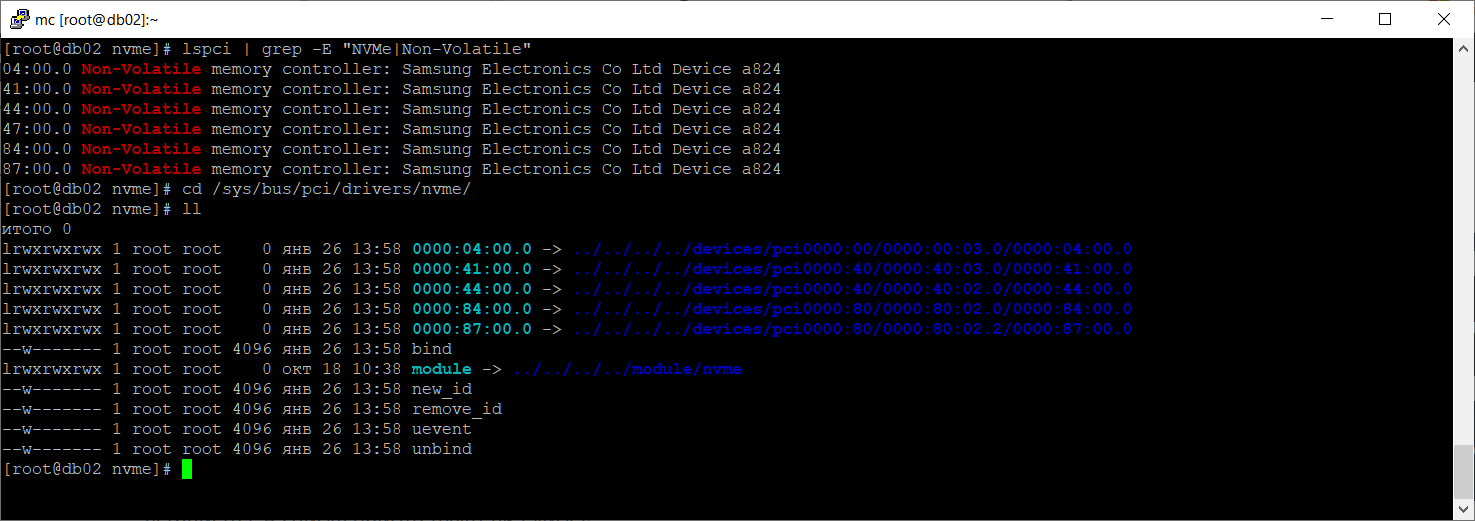
Драйвер устройства 0000:47:00.0 отсутствует, остальные есть. Удаляем отсутствующий диск из списка устройств и заново сканируем PCI.
echo 1 > /sys/bus/pci/devices/0000\:47\:00.0/remove
echo 1 > /sys/bus/pci/rescan
Здесь самое важное, не удалить что-нибудь не то. Если ошибиться с диском, то можно потерять данные.
nvme list
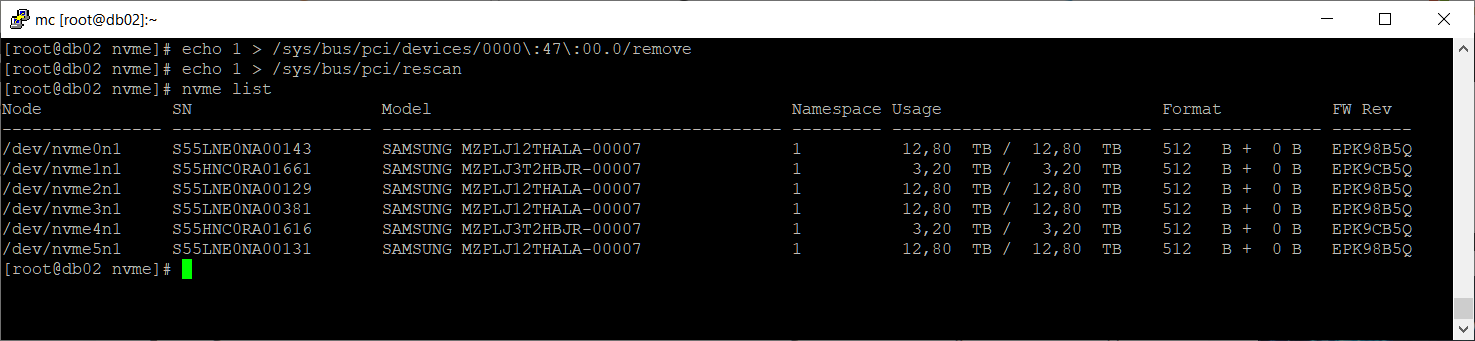
Диск /dev/nvme3n1 появился. Проверим ошибки:
nvme smart-log /dev/nvme3n1
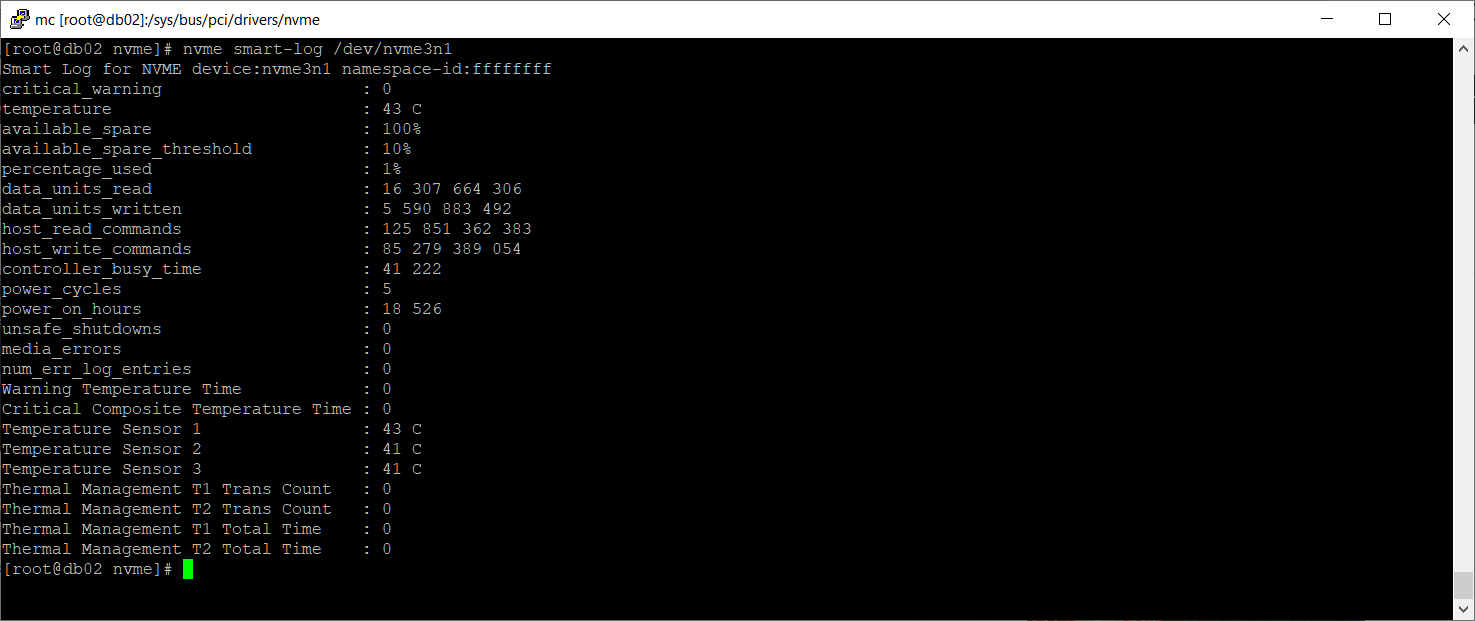
Странно, ошибок нет. Вероятно, сбой произошёл не по причине неисправности диска. Проверим namespace:
nvme id-ns /dev/nvme3n1
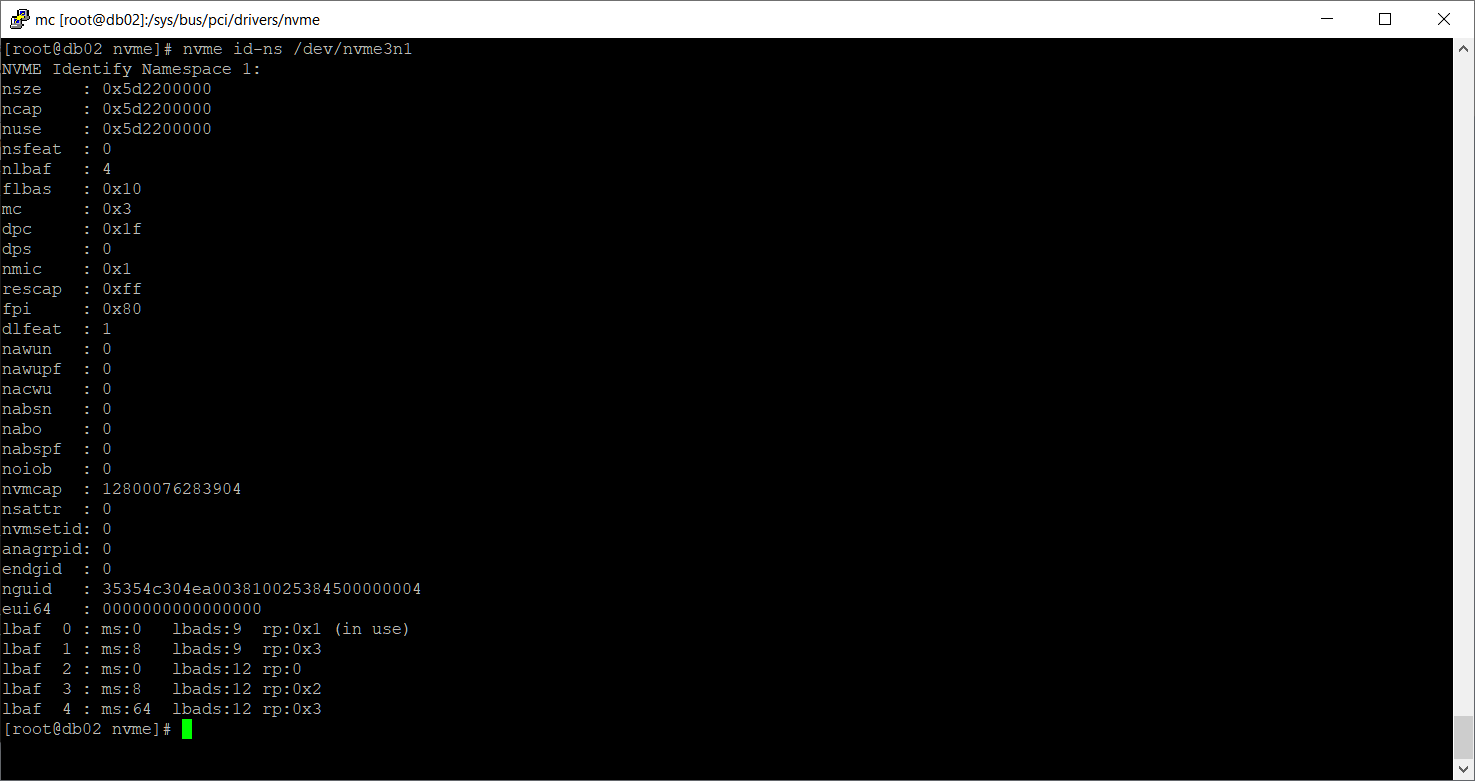
Namespace существует. Посмотрим раздел.
lsblk
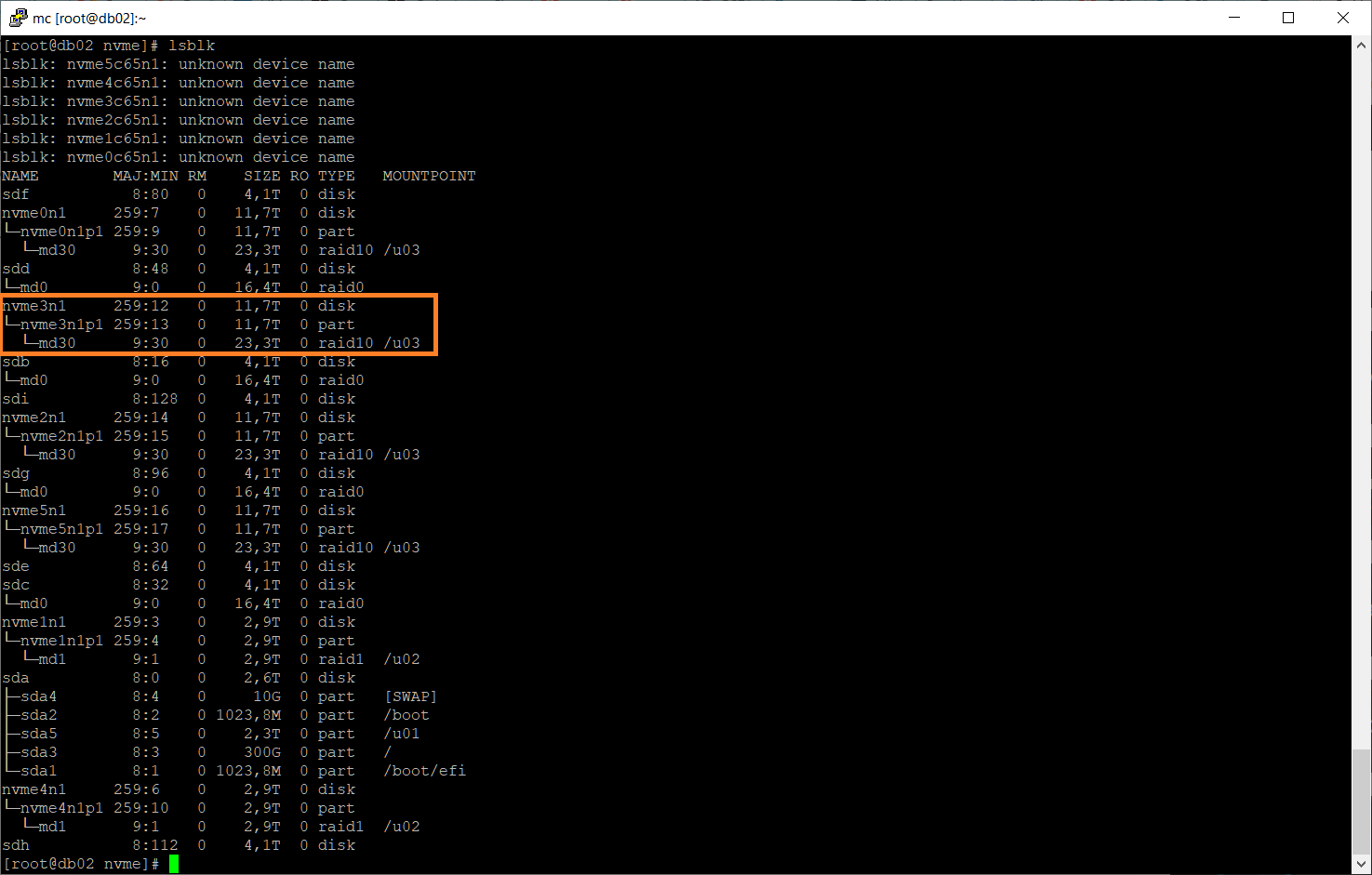
Раздел /dev/nvme3n1p1 существует. Поскольку раздел ещё числится в массиве как сбойный, выкинем его оттуда:
mdadm /dev/md30 --remove /dev/nvme3n1p1
mdadm --detail /dev/md30
Теперь сбойных дисков в массиве не числится.
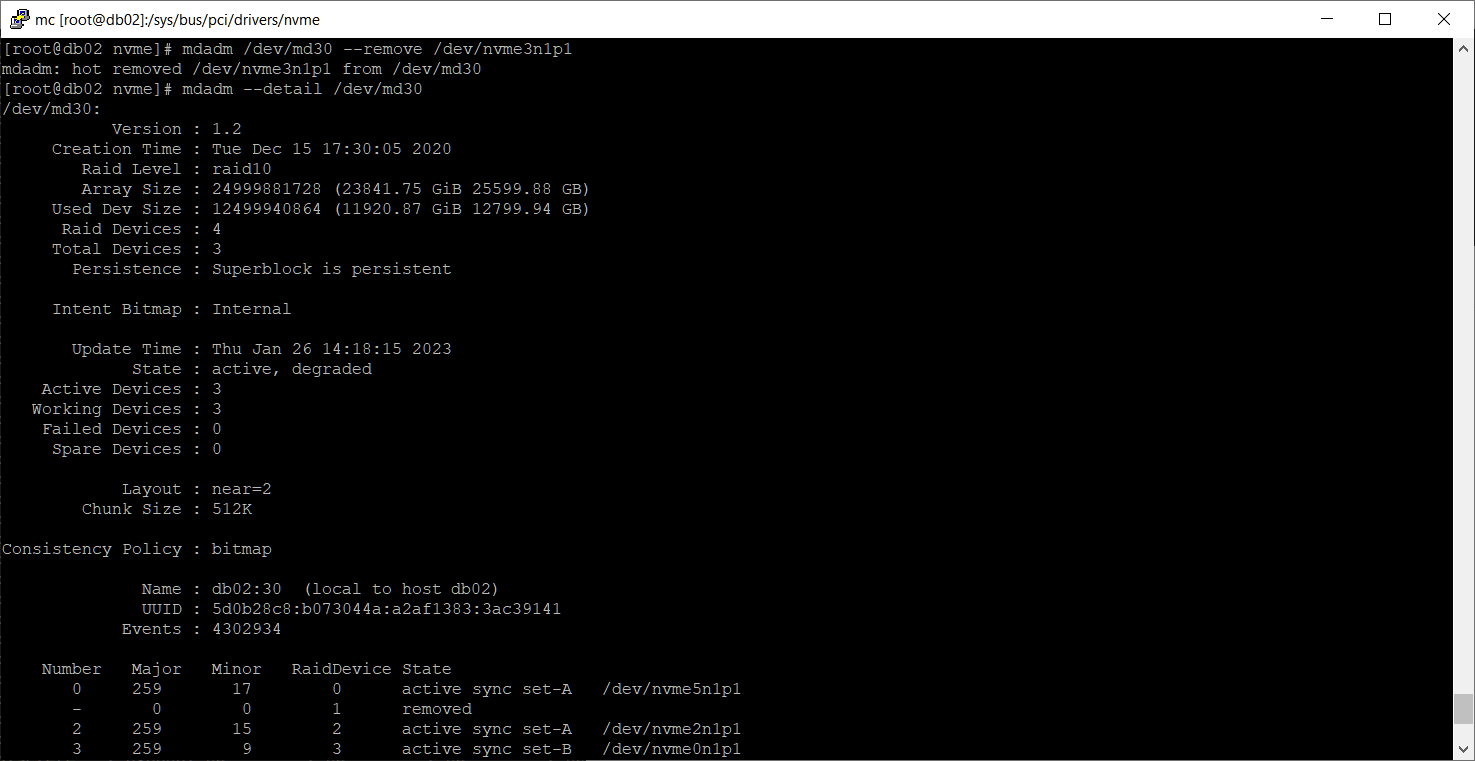
Возвращаем диск в массив.
mdadm /dev/md30 --add /dev/nvme3n1p1
cat /proc/mdstat
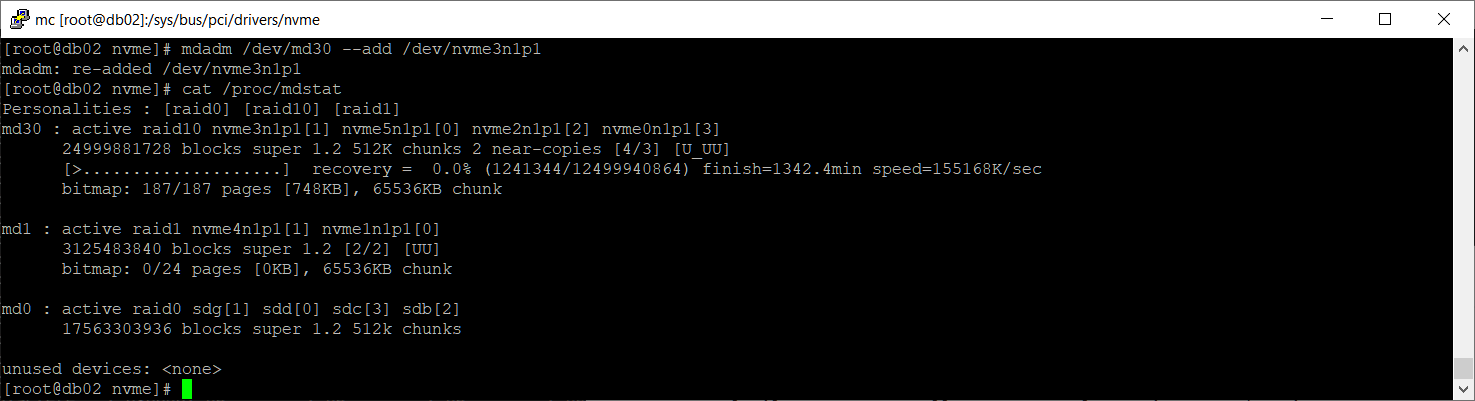
Массив начал восстанавливаться.
mdadm --detail /dev/md30
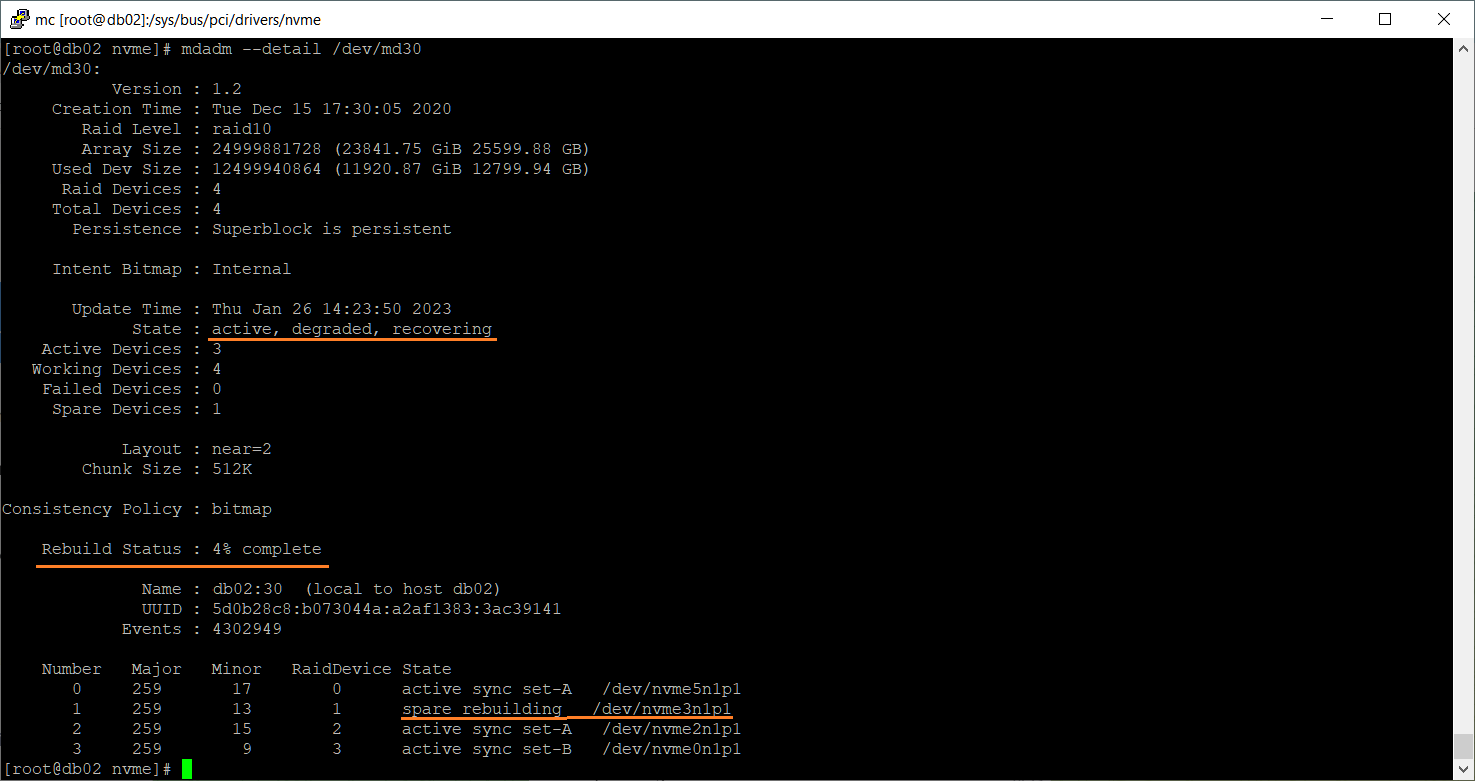
Осталось дождаться окончания процедуры перестроения массива.



















