


Полезные утилиты в копилку системного администратора для траблшутинга проблем дисковой подсистемы. Если дисковая подсистема не справляется, это может привести к проблемам самих сервисов, работающих на данном сервере.
Если сервер аппаратный, там проблема может быть более явной. На виртуальной машине проблема может ничем не проявляться кроме тормозов в работе сервисов.
Работаю сегодня на Ubuntu 20.04.6 LTS. Расскажем про iostat и iotop.
Для чего мониторить дисковую подсистему?
Для системного администратора или DevOps-инженера мониторинг ввода-вывода (I/O) — это базовый навык. Работать без него — всё равно что пытаться починить сложный механизм в полной темноте. Утилиты мониторинга дисковой подсистемы — ваш основной и незаменимый инструмент: они дают быстрый, простой и наглядный снимок текущей ситуации с дисками.
Выявление узких мест производительности
Часто причина зависаний кроется не в процессоре или оперативной памяти, а в чрезмерной нагрузке на дисковую подсистему (много операций чтения/записи).
Обнаружение скрытых потребителей
Бывают ситуации, когда фоновый процесс, служба или контейнер начинают активно записывать логи, генерировать временные файлы или кэшировать данные, и эта активность не всегда очевидна в стандартных мониторах вроде top или htop.
Обоснование модернизации и настройки
Анализ того, какие именно задачи нагружают диски, даёт чёткое понимание для принятия решений: нужен ли переход на SSD, требуется ли настройка RAID-массива или достаточно оптимизировать работу приложений.
iostat
Утилиту iostat можно использовать для оптимизации работы системы.
iostat — утилита командной строки в Linux, которая с собирает и показывает статистику по CPU и дисковому вводу-выводу (I/O).
Утилита можно не входить в базовый набор пакетов, но её можно установить с пакетом sysstat:
apt install sysstatИспользовать просто.
iostat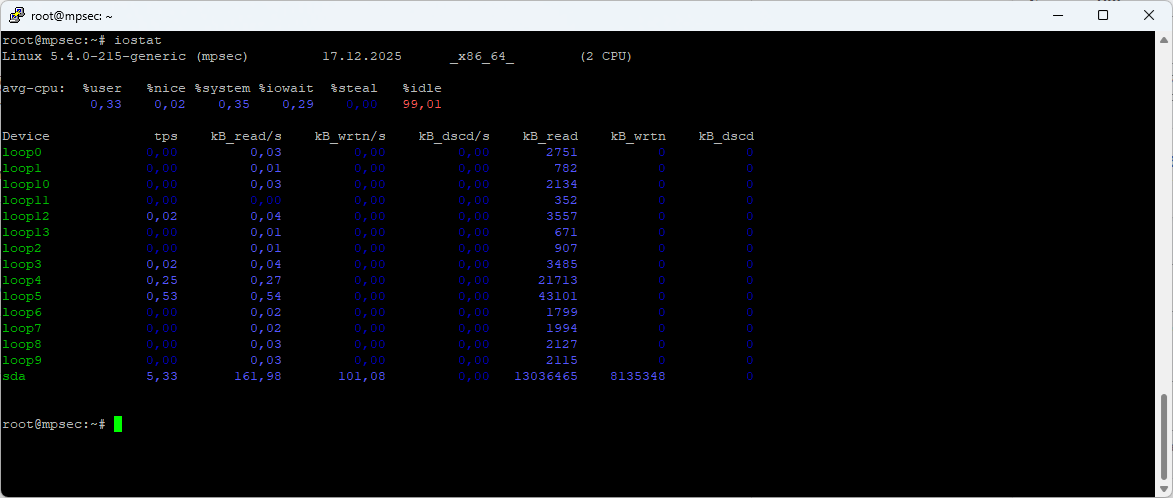
Команда iostat формирует два типа отчётов: отчёт об использовании CPU и отчёт об использовании устройств.
Первый отчёт, генерируемый командой iostat, — это отчёт об использовании CPU. Для многопроцессорных систем значения CPU представляют собой глобальные средние значения по всем процессорам. Отчёт имеет следующий формат:
- %user
Показывает процент использования CPU при выполнении задач на уровне пользователя (приложения). - %nice
Показывает процент использования CPU при выполнении задач на уровне пользователя с приоритетом nice. - %system
Показывает процент использования CPU при выполнении задач на системном уровне (ядро). - %iowait
Показывает процент времени, в течение которого CPU или CPUs простаивали, в то время как в системе имелся необработанный запрос дискового ввода-вывода. - %steal
Показывает процент времени, который виртуальный CPU или CPUs провели в вынужденном ожидании, пока гипервизор обслуживал другой виртуальный процессор. - %idle
Показывает процент времени, в течение которого CPU или CPUs простаивали, и в системе не было необработанных запросов дискового ввода-вывода.
Второй отчёт, генерируемый командой iostat, — это отчёт об использовании устройств. Этот отчёт предоставляет статистику для каждого физического устройства или раздела. Блочные устройства и разделы, для которых должна отображаться статистика, могут быть указаны в командной строке. Если ни устройство, ни раздел не указаны, то статистика отображается для каждого устройства, используемого системой, при условии, что ядро ведёт для него статистику. Если в командной строке указано ключевое слово ALL, то статистика отображается для всех устройств, определённых в системе, включая те, которые никогда не использовались. По умолчанию скорости передачи данных показаны в блоках по 1 КБ, если только не установлена переменная окружения POSIXLY_CORRECT, в этом случае используются блоки по 512 байт. В отчёте могут отображаться следующие поля в зависимости от использованных флагов:
- Device:
В этой колонке указано имя устройства (или раздела), как оно перечислено в каталоге /dev. - tps
Указывает количество операций передачи данных в секунду, отправленных на устройство. Передача — это запрос ввода-вывода к устройству. Несколько логических запросов могут быть объединены в один запрос ввода-вывода к устройству. Размер передачи не определён. - Blk_read/s (kB_read/s, MB_read/s)
Указывает объём данных, считанных с устройства, выраженный в количестве блоков (килобайт, мегабайт) в секунду. Блоки эквивалентны секторам и, следовательно, имеют размер 512 байт. - Blk_wrtn/s (kB_wrtn/s, MB_wrtn/s)
Указывает объём данных, записанных на устройство, выраженный в количестве блоков (килобайт, мегабайт) в секунду. - Blk_dscd/s (kB_dscd/s, MB_dscd/s)
Указывает объём данных, отброшенных (discarded) для устройства, выраженный в количестве блоков (килобайт, мегабайт) в секунду. - Blk_read (kB_read, MB_read)
Общее количество считанных блоков (килобайт, мегабайт). - Blk_wrtn (kB_wrtn, MB_wrtn)
Общее количество записанных блоков (килобайт, мегабайт). - Blk_dscd (kB_dscd, MB_dscd)
Общее количество отброшенных блоков (килобайт, мегабайт). - r/s
Количество (после объединения) успешно выполненных запросов на чтение в секунду для устройства. - w/s
Количество (после объединения) успешно выполненных запросов на запись в секунду для устройства. - d/s
Количество (после объединения) успешно выполненных запросов на отбрасывание (discard) в секунду для устройства. - sec/s (kB/s, MB/s)
Количество секторов (килобайт, мегабайт), считанных с устройства, записанных на него или отброшенных для него в секунду. - rsec/s (rkB/s, rMB/s)
Количество секторов (килобайт, мегабайт), считанных с устройства в секунду. - wsec/s (wkB/s, wMB/s)
Количество секторов (килобайт, мегабайт), записанных на устройство в секунду. - dsec/s (dkB/s, dMB/s)
Количество секторов (килобайт, мегабайт), отброшенных для устройства в секунду. - rqm/s
Количество запросов ввода-вывода, объединённых в секунду и поставленных в очередь к устройству. - rrqm/s
Количество запросов на чтение, объединённых в секунду и поставленных в очередь к устройству. - wrqm/s
Количество запросов на запись, объединённых в секунду и поставленных в очередь к устройству. - drqm/s
Количество запросов на отбрасывание (discard), объединённых в секунду и поставленных в очередь к устройству. - %rrqm
Процент запросов на чтение, объединённых вместе перед отправкой на устройство. - %wrqm
Процент запросов на запись, объединённых вместе перед отправкой на устройство. - %drqm
Процент запросов на отбрасывание (discard), объединённых вместе перед отправкой на устройство. - areq-sz
Средний размер (в килобайтах) запросов ввода-вывода, отправленных на устройство.
Примечание: В предыдущих версиях это поле называлось avgrq-sz и выражалось в секторах. - rareq-sz
Средний размер (в килобайтах) запросов на чтение, отправленных на устройство. - wareq-sz
Средний размер (в килобайтах) запросов на запись, отправленных на устройство. - dareq-sz
Средний размер (в килобайтах) запросов на отбрасывание (discard), отправленных на устройство. - await
Среднее время (в миллисекундах), затраченное на обслуживание запросов ввода-вывода, отправленных на устройство. Включает время нахождения запросов в очереди и время их непосредственного выполнения. - r_await
Среднее время (в миллисекундах), затраченное на обслуживание запросов на чтение, отправленных на устройство. Включает время нахождения запросов в очереди и время их непосредственного выполнения. - w_await
Среднее время (в миллисекундах), затраченное на обслуживание запросов на запись, отправленных на устройство. Включает время нахождения запросов в очереди и время их непосредственного выполнения. - d_await
Среднее время (в миллисекундах), затраченное на обслуживание запросов на отбрасывание (discard), отправленных на устройство. Включает время нахождения запросов в очереди и время их непосредственного выполнения. - qu-sz
Средняя длина очереди запросов, отправленных на устройство.
Примечание: В предыдущих версиях это поле называлось avgqu-sz. - %util
Процент времени, в течение которого на устройство отправлялись запросы ввода-вывода (загрузка пропускной способности устройства). Насыщение устройства наступает, когда это значение близко к 100% для устройств, обслуживающих запросы последовательно. Однако для устройств, обслуживающих запросы параллельно (таких как RAID-массивы и современные SSD), это число не отражает их реальных пределов производительности.
Отчёт по умолчанию показывает не всё, изучите мануал.
man iostatОпции iostat
- -c
Отобразить отчёт об использовании CPU. - -d
Отобразить отчёт об использовании устройств. - --dec={ 0 | 1 | 2 }
Указать количество знаков после десятичной точки для отображения (от 0 до 2, значение по умолчанию — 2). - -g имя_группы { устройство [...] | ALL }
Отобразить статистику для группы устройств. Команда iostat выводит статистику для каждого отдельного устройства в списке, а затем строку с общей статистикой для группы, которая отображается под именем имя_группы и состоит из всех устройств в списке. Ключевое слово ALL означает, что в группу должны быть включены все блочные устройства, определённые системой. - -H
Эта опция должна использоваться вместе с опцией-gи указывает, что должны отображаться только общие статистические данные по группе, а не статистика для отдельных устройств в группе. - -h
Сделать отчёт об использовании устройств более удобочитаемым для человека. С этой опцией неявно активируется--human. - --human
Выводить размеры в удобочитаемом для человека формате (например, 1.0k, 1.2M и т.д.). Единицы измерения, отображаемые с этой опцией, заменяют любые другие единицы по умолчанию (например, килобайты, секторы...), связанные с метриками. - -j { ID | LABEL | PATH | UUID | ... } [ устройство [...] | ALL ]
Отображать постоянные имена устройств. Опции ID, LABEL и т.д. определяют тип постоянного имени. Эти опции не ограничены, единственное условие — наличие в системе каталога /dev/disk с требуемыми постоянными именами. Дополнительно можно указать несколько устройств в выбранном типе постоянного имени. Поскольку постоянные имена устройств обычно длинные, опция... - -k
Отображать статистику в килобайтах в секунду. - -m
Отображать статистику в мегабайтах в секунду. - -N
Отображать зарегистрированные имена Device Mapper для любых устройств Device Mapper. Полезно для просмотра статистики LVM2. - -o JSON
Отображать статистику в формате JSON (JavaScript Object Notation). Порядок полей в выводе JSON не определён, и в будущем могут быть добавлены новые поля. - -p [ { устройство [,...] | ALL } ]
Опция -p отображает статистику для блочных устройств и всех их разделов, используемых системой. Если имя устройства указано в командной строке, отображается статистика для него и всех его разделов. Наконец, ключевое слово ALL указывает, что статистика должна быть отображена для всех блочных устройств и разделов, определённых системой, включая те, которые никогда не использовались. Если перед этой опцией задана опция -j, устройства в командной строке могут быть указаны с помощью выбранного типа постоянного имени. - -s
Отобразить короткую (узкую) версию отчёта, которая должна помещаться на экранах шириной 80 символов. - -t
Выводить время для каждого отображаемого отчёта. Формат времени может зависеть от значения переменной окружения S_TIME_FORMAT (см. ниже). - -V
Вывести номер версии. - -x
Отобразить расширенную статистику. - -y
Пропустить первый отчёт со статистикой с момента загрузки системы, если отображается несколько записей с заданным интервалом. - -z
Указать iostat пропускать вывод для любых устройств, на которых не было активности в течение периода сбора данных.
Бывает что нагрузка на дисковую систему непостоянная, в динамике можно смотреть с помощью watch;
watch iostat -xwatch — утилита в операционной системе Unix, которая запускает определённую программу через фиксированный интервал времени и отображает вывод этой программы в окне терминала.
iotop
Утилита iotop не вмешивается в работу процессов, не тормозит систему и почти не потребляет ресурсы. Всё, что он делает — читает статистику и красиво её выводит. iotop использует интерфейсы ядра (procfs, sysfs и taskstats), чтобы вытащить статистику по каждому процессу.
Утилита можно не входить в базовый набор пакетов, но её можно установить с пакетом iotop:
apt install iotopIotop — утилита командной строки в Linux, которая мониторит использование дискового ввода-вывода (I/O) в режиме реального времени.
Использовать просто.
iotop
Утилита похожа на top, но фокусируется именно на I/O (Input/Output) — чтение и запись на диск.
Внизу экрана можно найти некоторые команды, которые можно вызвать нажатиями на клавиши клавиатуры. Например, o скрывает (или отображает) все неактивные процессы. Это позволяет уменьшить большой объём сведений.
Что можно увидеть?
- Total DISK READ / DISK WRITE — общая статистика по вводу выводу
- Curent DISK READ / DISK WRITE — текущая статистика обращения к дискам, не учитывается cache и buffur, не учитываются операции ввода вывода внутри ядра
- TID — номер потока
- PRIO — приоритет
- USER — от какого пользователя запущен процесс
- DISK READ/WRITE — скорость чтения/записи (в KB/s или MB/s)
- SWAPIN — процент времени, когда процесс перемещает данные между RAM и swap
- IO — процент времени, когда процесс ждёт завершения I/O
- COMMAND — команда, которой запущен процесс
Что ещё?
Для мониторинга дисковой подсистемы могут пригодиться:
dstat— Универсальный инструмент для мониторинга различных системных ресурсов, включая дисковый ввод-вывод. Позволяет получить полный обзор производительности системы в режиме реального времени.atop— Утилита мониторинга системы для Linux, которая отображает загрузку системных ресурсов в реальном времени. Она не только показывает текущие данные, но и сохраняет исторические для анализа.sar— утилита в Linux, которая собирает, отображает и сохраняет информацию о деятельности системы. Она помогает администраторам систем анализировать производительность, выявлять узкие места и оптимизировать распределение ресурсов. Входит в sysstat.glances— Консольный инструмент мониторинга на Python. Отображает данные о различных системных ресурсах в режиме реального времени.pidstat— Утилита, используемая для мониторинга и отчётности по статистике производительности процессов. Она может контролировать либо конкретный процесс, либо все запущенные процессы в системе. Входит в sysstat.btrace— Запускает трассировку драйвера блочного устройства в ядре и возвращает данные трассировки.iosnoop— Утилита для анализа событий ввода-вывода (I/O) на блочных устройствах в Linux. Умеет показывать latency.biosnoop,biotop,bitesize,blktrace,collectl,vmstat,nmon,iolatency,ext4slower...




















