


В процессе администрирования кластера Kubernetes у системных администраторов часто возникают задачи по обслуживанию нод кластера. Иногда нужно выключить физическую ноду для технического обслуживания или апгрейда. Если нода виртуальная, то может понадобиться выключение для апгрейда системных ресурсов.
Краткая инструкция по вводу ноды в режим обслуживания и выводу из него.
Kubernetes — проект с открытым исходным кодом для оркестрации кластера контейнеров Linux. Kubernetes управляет и запускает контейнеры Docker на большом количестве хостов, а так же обеспечивает совместное размещение и репликацию большого количества контейнеров.
Имеем кластер из тридцати с лишним серверов.
kubectl get node
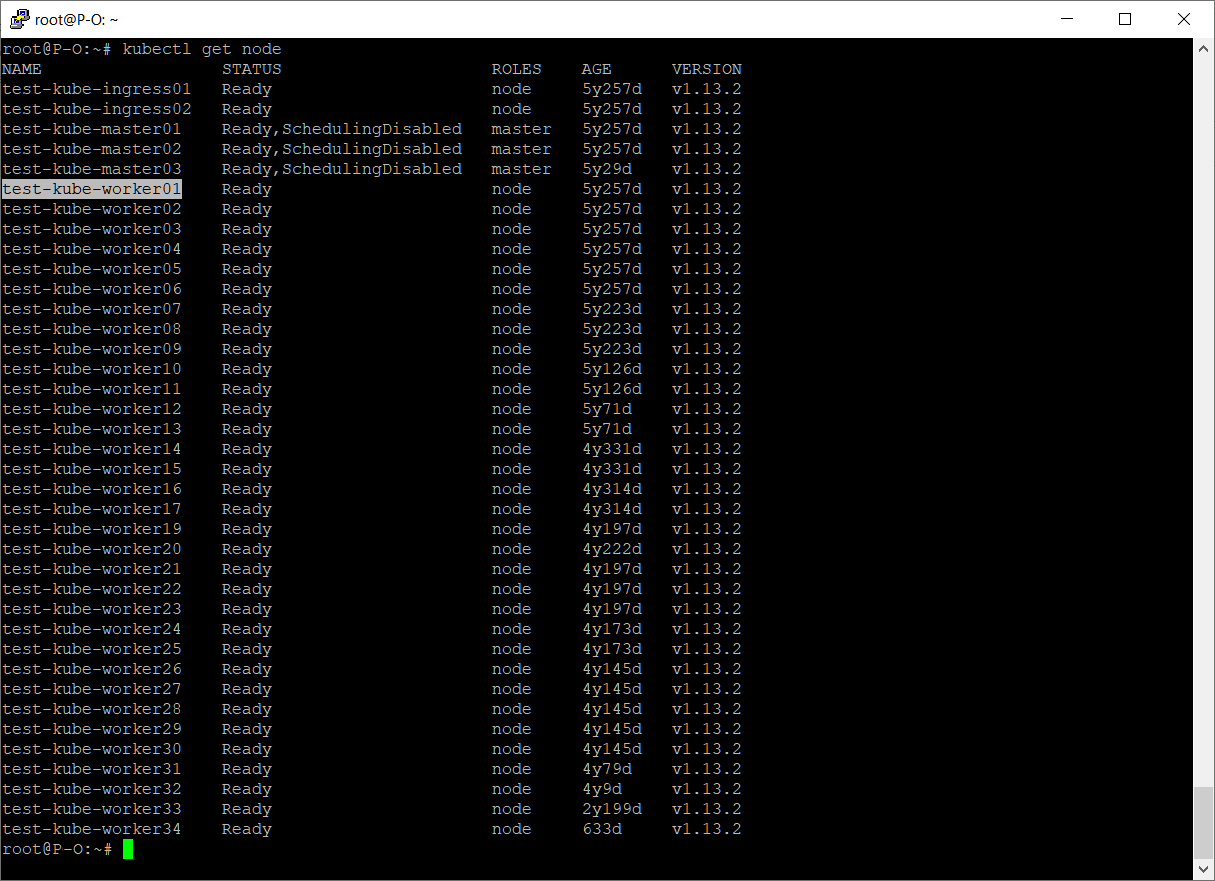
Ноду test-kube-worker01 планируется отключить и добавить немного памяти и процессоров. Нам нужно будет ввести ноду в режим обслуживания, выключить, добавить ресурсов, включить и вывести из режима обслуживания.
При этом мы хотим корректно завершить работу подов на выбранной ноде.
Ввод ноды в режим обслуживания
Выполняю команду:
kubectl drain --ignore-daemonsets --delete-local-data test-kube-worker01
- kubectl drain — данная команда переводит ноду в режим обслуживания. Поды на указанной ноде корректно завершают работу, или киляются по таймауту, если они так и не успели выключиться. Не все поды завершают работу по умолчанию. Все поды, запущенные на выбранном узле, будут поставлены в состояние "Terminating" и перенесены на другие доступные узлы в кластере. Replication Controllers, ReplicaSets и Deployments, управляющие переносимыми подами, будут создавать новые поды на других узлах для поддержания желаемого количества запущенных подов.
- ignore-daemonsets — этот параметр нужен для того, чтобы игнорировать поды, созданные через DaemonSets. DaemonSets-поды должны работать на каждом узле, например, для мониторинга или сетевых служб.
- delete-local-data (deprecated) — удаляет поды, использующие EmptyDir (локальные данные будут удалены)
Flag --delete-local-data has been deprecated, This option is deprecated and will be deleted. Use --delete-emptydir-data.
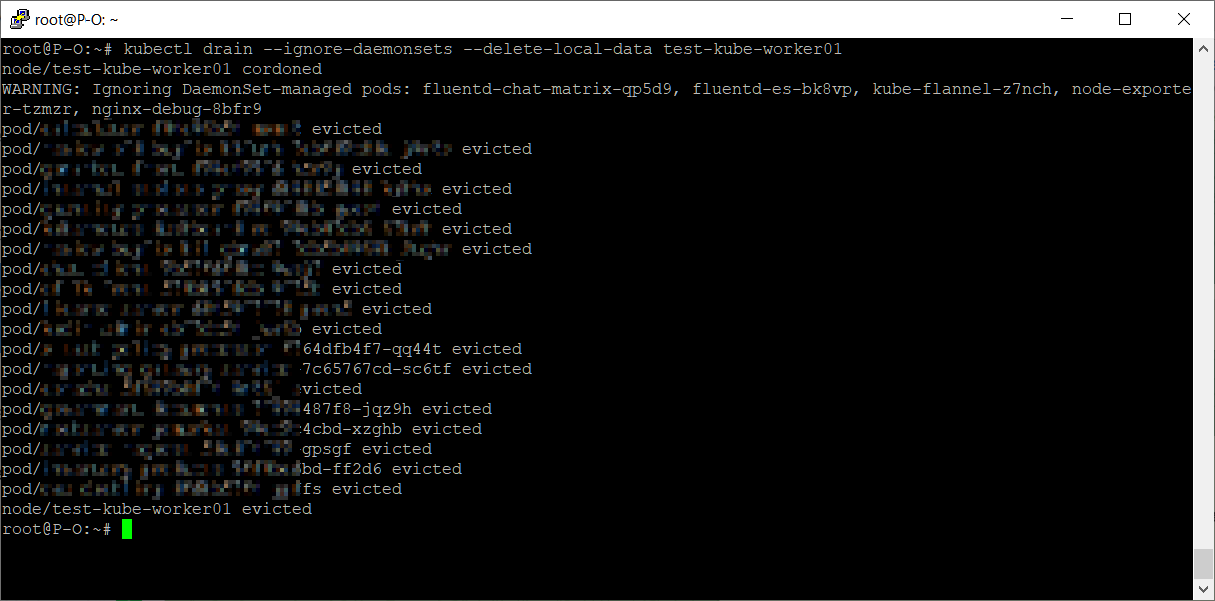
Все поды, кроме созданных через DaemonSets, корректно завершили работу на выбранной ноде и будут подняты на какой-то другой.
kubectl get node
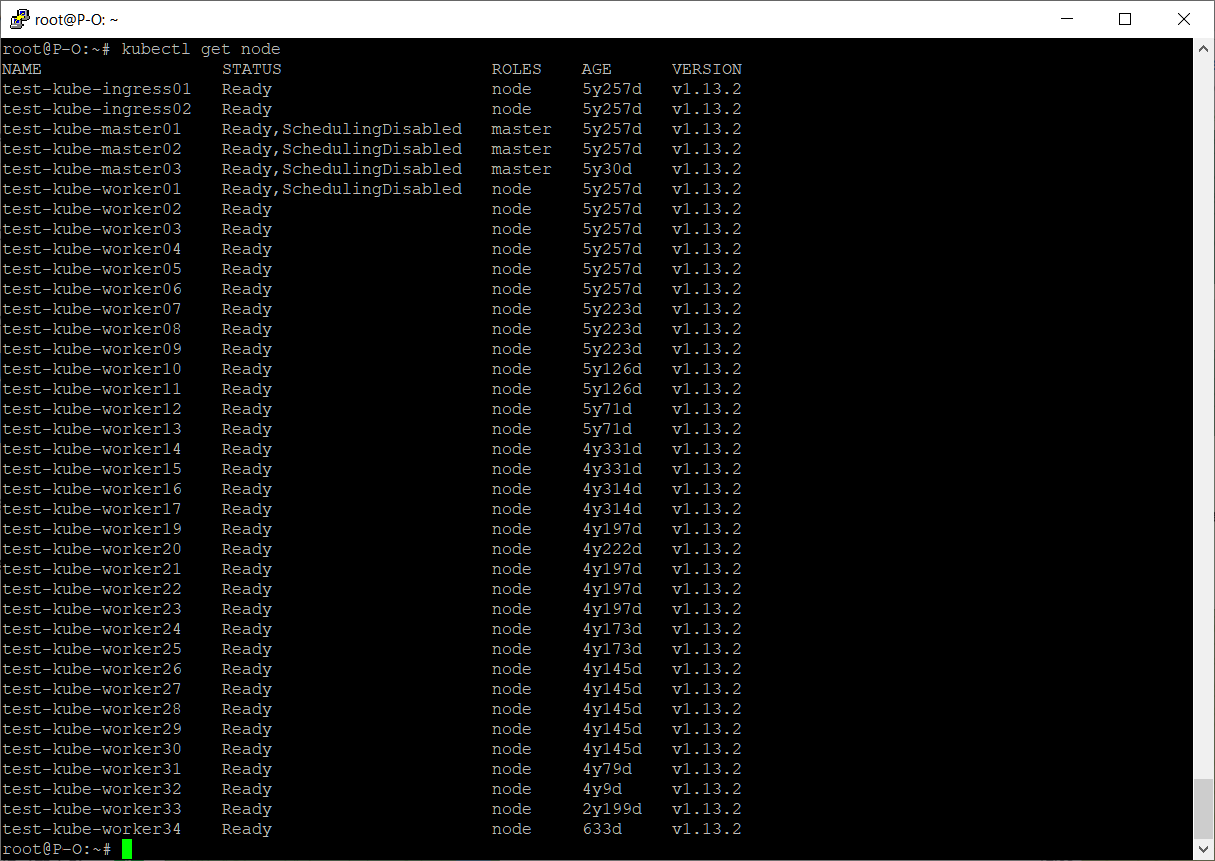
У ноды появился статус SchedulingDisabled. Значит, новые поды на ноде запускаться не будут.
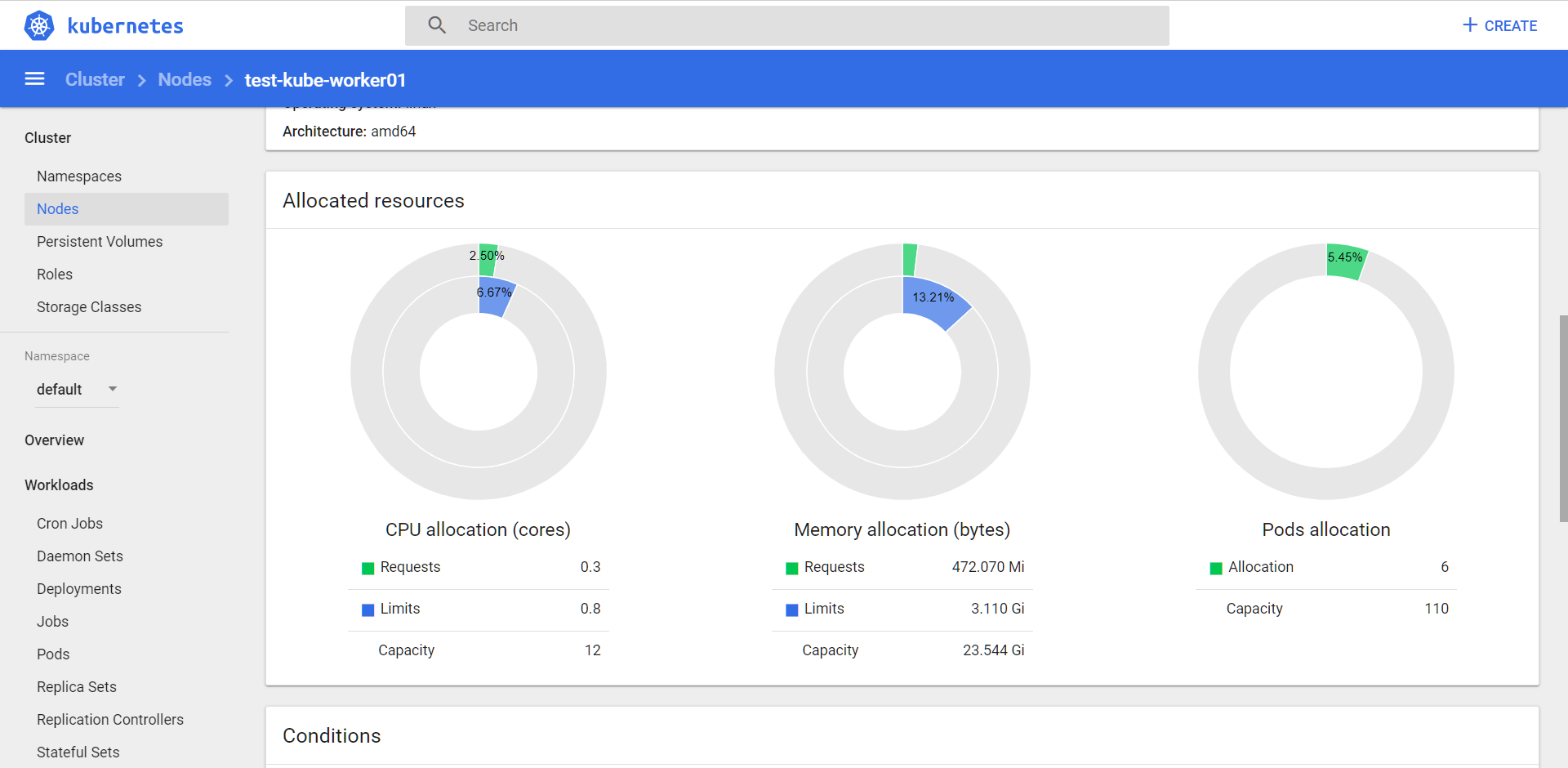
У ноды 12 CPU и 24 ГБ RAM.
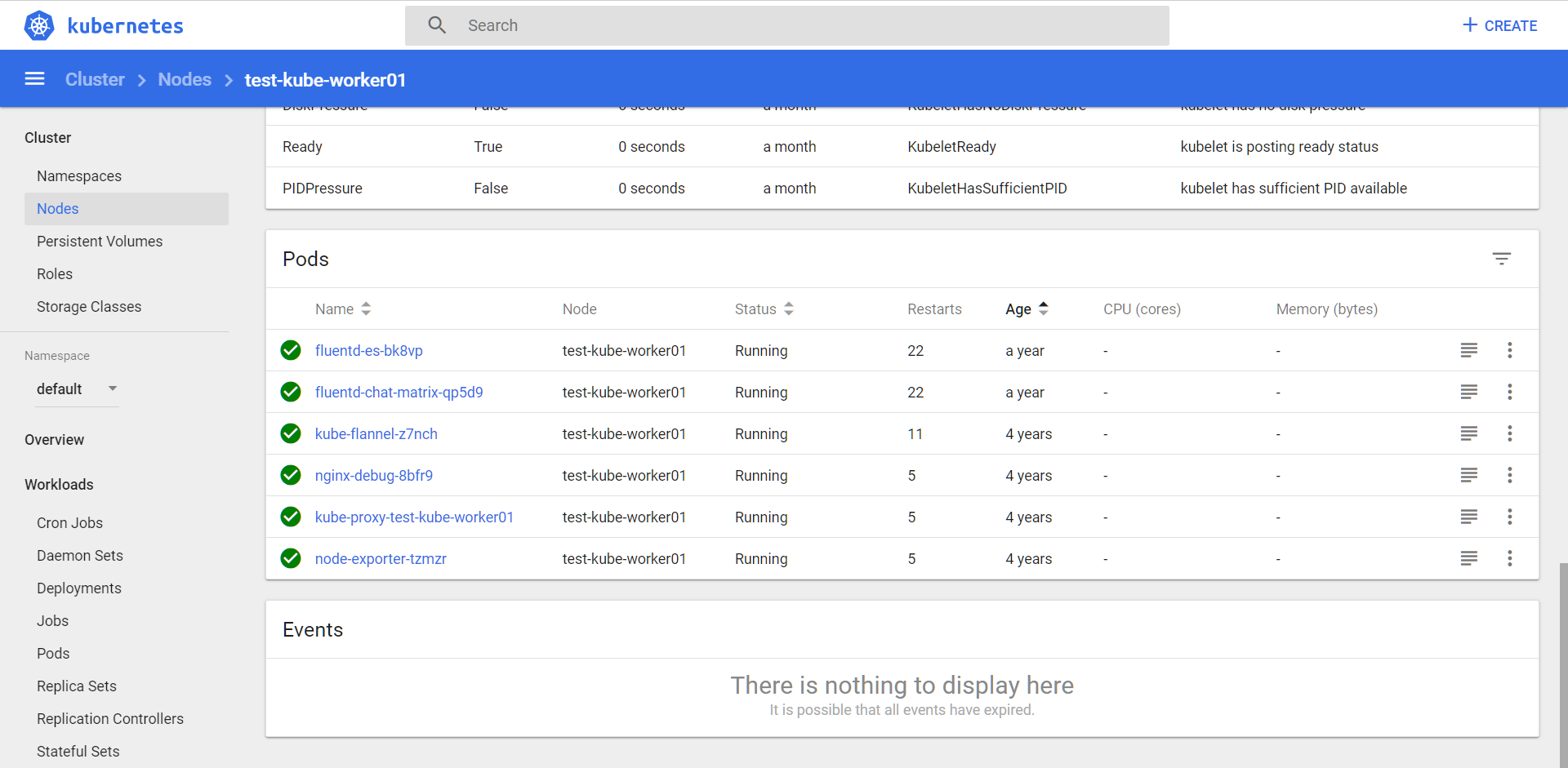
Список подов, которые остались на ноде. Они нам не помешают. Выключаем ноду, добавляем в неё CPU и память, включаем снова.
kubectl get node
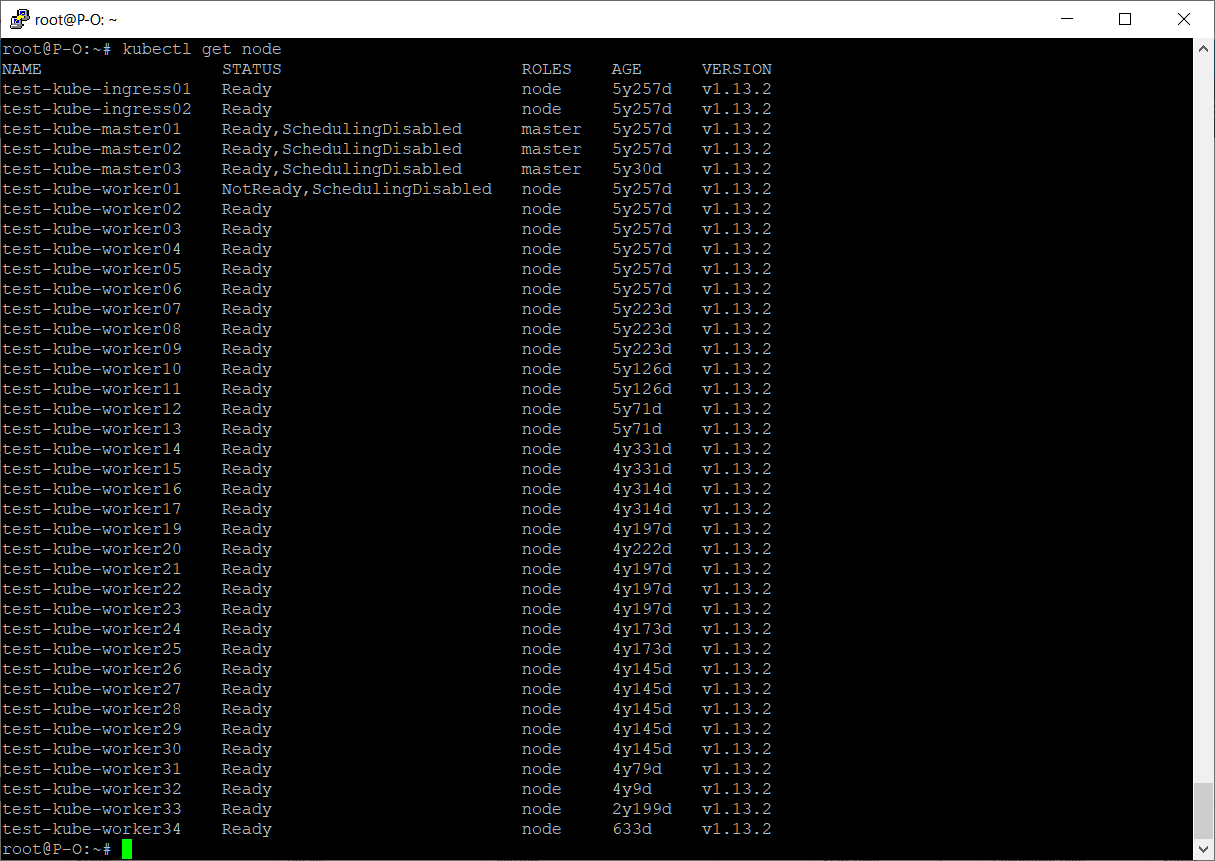
Статус выключенной ноды: NotReady,SchedulingDisabled.
Спокойно добавляем CPU и память, включаем ноду.
kubectl get node
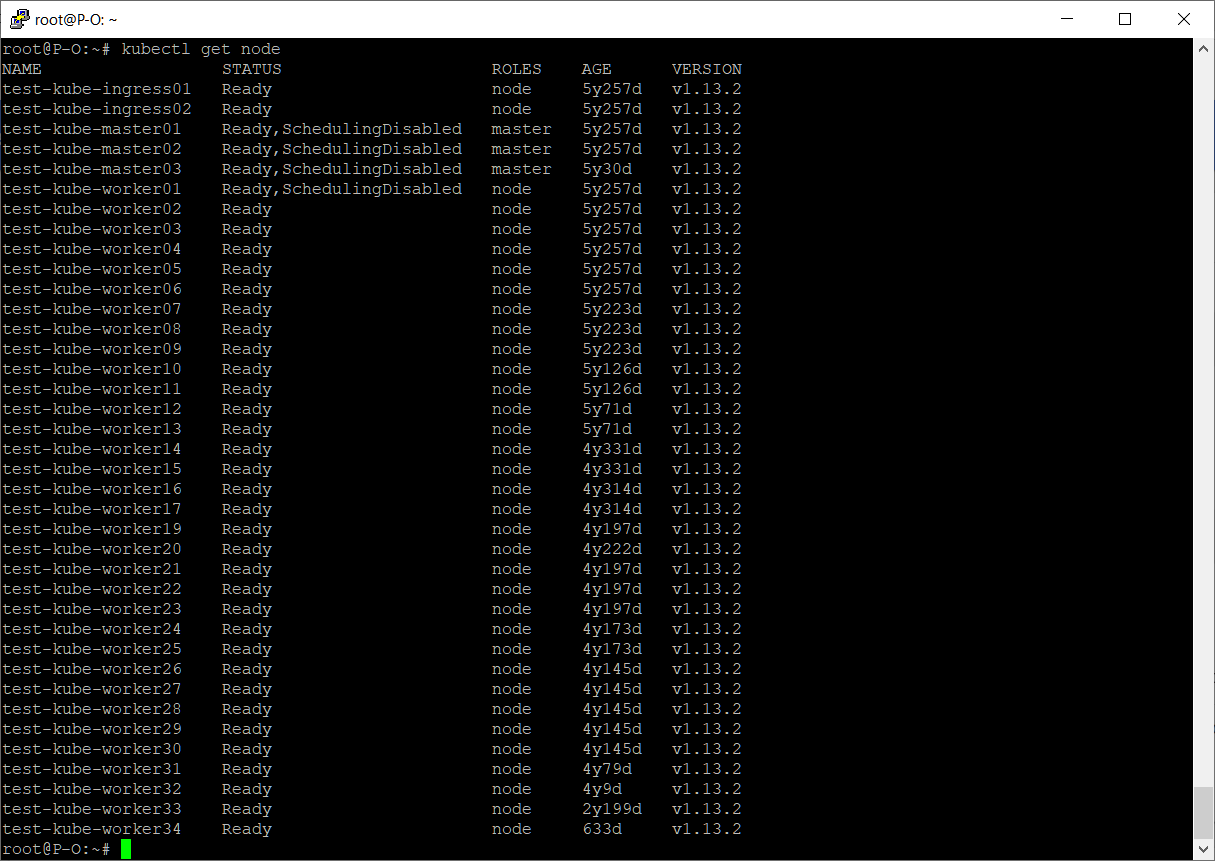
Дожидаемся, когда статус ноды сменится на Ready,SchedulingDisabled.
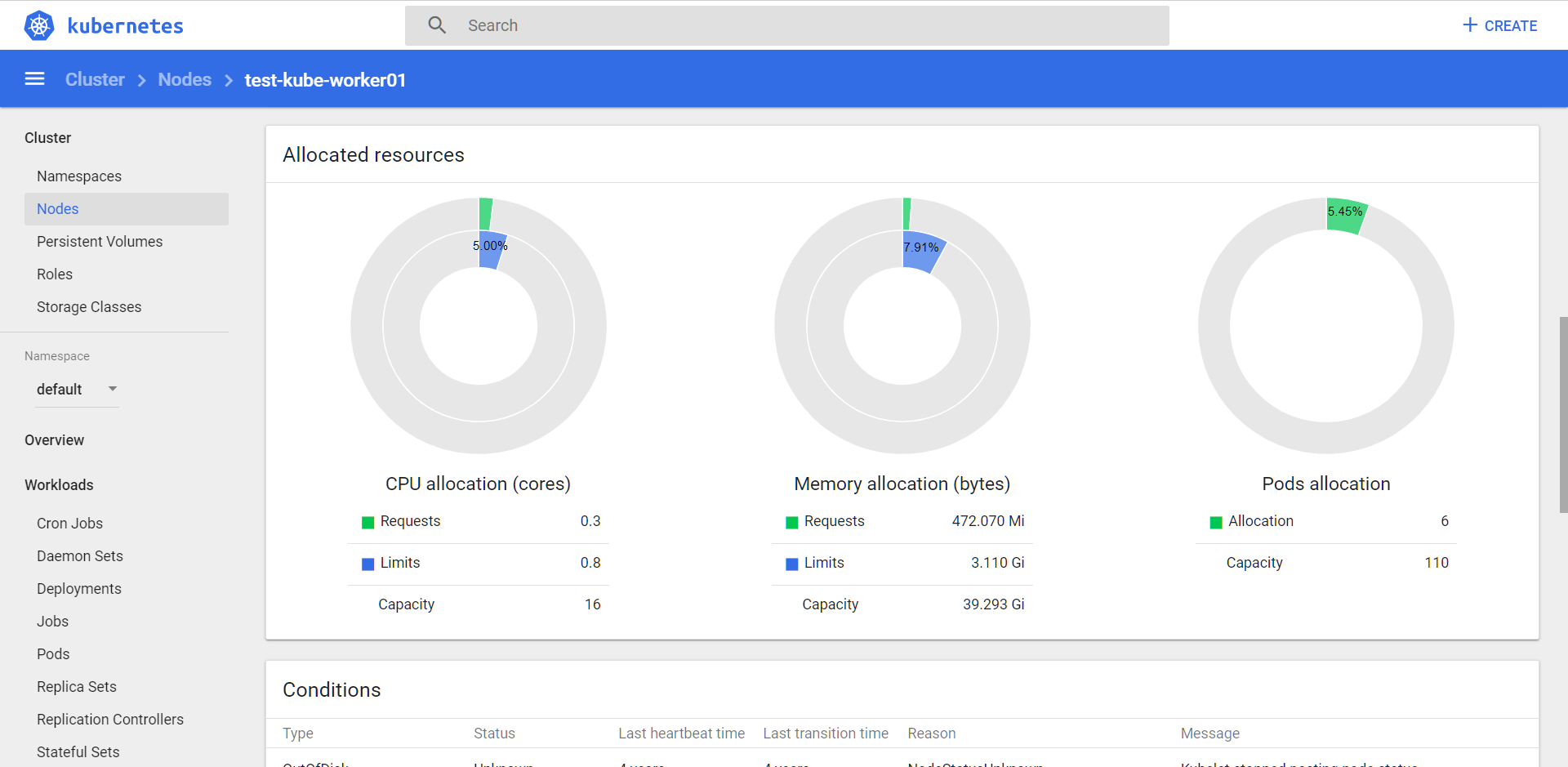
Ресурсов стало больше: 16 CPU и 40 ГБ RAM.
Вывод ноды из режима обслуживания
Выводим ноду из режима обслуживания.
kubectl uncordon test-kube-worker01

kubectl get node
Статус ноды Ready.
Примечания
Можно отслеживать количество подов на ноде командой:
kubectl get pods -o wide --all-namespaces | grep <имя_узла>
Посмотреть статус ноды:
kubectl get node | grep <имя_узла>
Запретить создавать новые поды на ноде, при этом старые поды не удалять:
kubectl cordon <имя_узла>
С помощью cordon можно предотвратить размещение планировщиком новых подов на хосте, при этом не оказывая влияние на существующие поды. Это полезно в качестве подготовительного шага перед перезагрузкой узла или другим обслуживанием. Статус ноды при этом Ready,SchedulingDisabled.






















