


Сегодня исправляем ошибку, связанную с большим количеством отозванных сертификатов. Я до ошибки не довёл, но лучше перебдеть, чем недобдеть.
Логинимся в vCenter под рутом и выполняем команду:
/usr/lib/vmware-vmafd/bin/vecs-cli entry list --store TRUSTED_ROOT_CRLS | grep Number
Данный запрос выведет количество отозванных сертификатов, которые лежат в хранилище TRUSTED_ROOT_CRLS. Если результат покажет значение в сотни или тысячи, то нужно чистить.
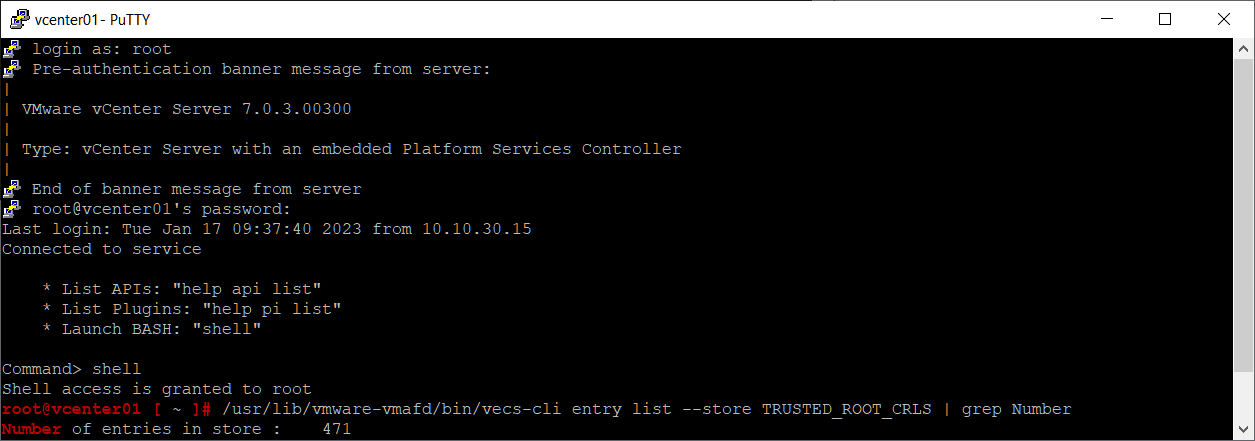
У меня в хранилище 471 отозванный сертификат, это не очень хорошо, но ещё не критично.
При каждой проверке сертификата vCenter проверяет, не содержится ли он в списке отозванных. Эта процедура занимает некоторое время, чем больше хранилище отозванных сертификатов, тем больше времени нужно на проверку. В результате начинают отваливаться по таймауту службы.
Возможные проблемы
Службы VMware-vPostgres, vmware-vpxd-svcs и vmware-vpxd не стартуют. При коннекте к базе vCenter Database ошибки:
Failed to connect to database: ODBC error: (08001) - [unixODBC]could not connect to server: Connection refused --> Is the server running on host "localhost" (127.0.0.1) and accepting --> TCP/IP connections on port 5432?
Логи vPostgres не пишутся.
/var/log/vmware/vpostgres/postgresql-30.log
В логе /var/log/vmware/vpxd/vpxd.log можно встретить ошибку:
2020-07-07T20:18:01.671Z error vpxd[35339] [Originator@6876 sub=vpxdVdb] [VpxdVdb::SetDBType] Failed to connect to database: ODBC error: (08001) - [unixODBC]could not connect to server: Connection refused --> Is the server running on host "localhost" (127.0.0.1) and accepting --> TCP/IP connections on port 5432? --> Retry attempt: 16305 ...
В логе /var/log/vmware/vmon/vmon-syslog.log нет записей о том почему vmware-vpostgres не запускается:
2020-07-07T20:31:03.805884+00:00 notice vmon Received start request for vmware-vpostgres 2020-07-07T20:31:03.806089+00:00 notice vmon <vmware-vpostgres-prestart> Constructed command: /opt/vmware/vpostgres/current/scripts/pg_pre_start | | <vmware-vpostgres-prestart> Constructed command: /opt/vmware/vpostgres/current/scripts/pg_pre_start 2020-07-07T20:33:03.040400+00:00 notice vmon Executing service batch op API_HEALTH. IgnoreFail=1, service count=10 2020-07-07T20:33:03.040808+00:00 notice vmon <vapi-endpoint-healthcmd> Constructed command: /usr/bin/python /usr/lib/vmware-vmon/vmonApiHealthCmd.py -n vapi-endpoint -u /vapiendpoint/health -t 30 2020-07-07T20:33:03.041005+00:00 notice vmon <rhttpproxy-healthcmd> Constructed command: /usr/bin/python /usr/lib/vmware-rhttpproxy/rhttpproxy-vmon-apihealth.py 2020-07-07T20:33:03.041184+00:00 notice vmon <vmware-vpostgres> Skip service health check. State STOPPED, Curr request 1 2020-07-07T20:33:03.041356+00:00 notice vmon <vcha> Skip service health check. State STOPPED, Curr request 0 2020-07-07T20:33:03.041535+00:00 notice vmon <vmware-postgres-archiver> Skip service health check. State STOPPED, Curr request 0 2020-07-07T20:33:03.041711+00:00 notice vmon <vpxd-svcs> Skip service health check. State STOPPED, Curr request 0 2020-07-07T20:33:03.041882+00:00 notice vmon <vpxd> Skip service health check. State STOPPING, Curr request 1 2020-07-07T20:33:03.042051+00:00 notice vmon <sps> Skip service health check. State STOPPED, Curr request 0 2020-07-07T20:33:03.042221+00:00 notice vmon <rbd> Skip service health check. State STOPPED, Curr request 0 2020-07-07T20:33:03.042407+00:00 notice vmon <pschealth> Skip service health check. State STOPPED, Curr request 0 2020-07-07T20:33:03.354545+00:00 notice vmon Successfully executed service batch operation API_HEALTH.
В логе /var/log/vmware/vpxd-svcs/vpxd-svcs.log можно встретить ошибку:
SQL Error: org.apache.commons.dbcp.SQLNestedException: Cannot create PoolableConnectionFactory (Connection refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections.)
Что делать?
Можно выполнить скрипт crl-fix.sh для исправления, скрипт доступен здесь:
https://kb.vmware.com/s/article/80020
На самом деле скрипт маленький, можно и вручную создать.
cd /root
vim crl-fix.sh
Insert. Копируем в него содержимое:
#!/bin/bash
cd /etc/ssl/certs
mkdir /tmp/pems
mkdir /tmp/OLD-CRLS-CAs
mv *.pem /tmp/pems && mv *.* /tmp/OLD-CRLS-CAs
h=$(/usr/lib/vmware-vmafd/bin/vecs-cli entry list --store TRUSTED_ROOT_CRLS --text | grep Alias | cut -d : -f 2)
for hh in "echo "${h[@]}"";do echo "Y" | /usr/lib/vmware-vmafd/bin/vecs-cli entry delete --store TRUSTED_ROOT_CRLS --alias $hh;done
mv /tmp/pems/* .
for l in `ls *.pem`;do ln -s $l ${l/pem/0};done
service-control --stop vmafdd && service-control --start vmafdd
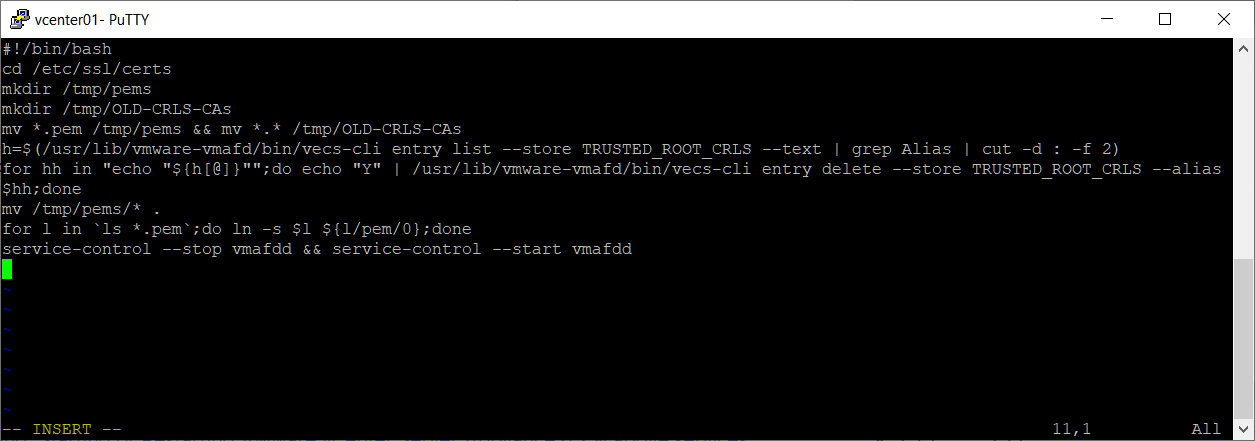
Сохраняем: Esc, :wq. Делаем скрипт исполняемым:
chmod +x crl-fix.sh
Запускаем:
./crl-fix.sh
Скрипт может работать долго.
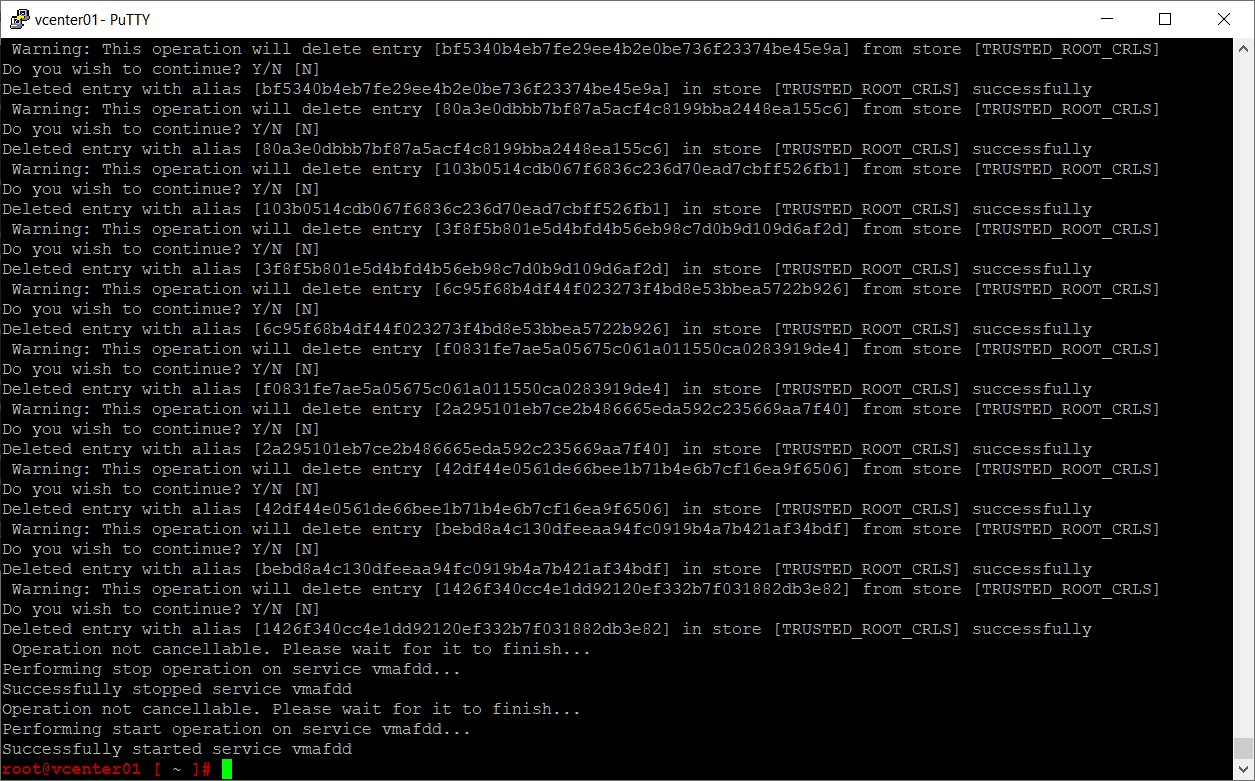
В конце увидим:
Operation not cancellable. Please wait for it to finish... Performing stop operation on service vmafdd... Successfully stopped service vmafdd Operation not cancellable. Please wait for it to finish... Performing start operation on service vmafdd... Successfully started service vmafdd
Перезапускаем службы:
service-control --stop --all
service-control --start --all
Проверяем что получилось:
/usr/lib/vmware-vmafd/bin/vecs-cli entry list --store TRUSTED_ROOT_CRLS | grep Number

vCenter стал работать раза в три быстрее! Полезный скрипт.





















