


Молодцы что заглянули к нам. Нам предстоит достаточно сложная задача, причём не на один день. Будем расширять программный mdadm массив RAID5 путём замены старых дисков на новые диски большего объёма. Я параллельно работаю сразу с двумя серверами, но это не принципиально.
Рабочий стенд:
- Сервер HPE Proliant DL360 Gen9.
- Три диска Samsung SSD 6.4TB PCIe MZPLL6T4HMLA-00005 (похожи на MZPLL6T4HMLA-00AD3)
- Операционная система Linux (не помню какая именно)
- RAID5 программный массив из трёх NVMe дисков.
С помощью пакета NVMe-CLI мы можем посмотреть текущий список NVMe дисков и их серийные номера. Серийники нам пригодятся, когда будем менять диски.
nvme list
cat /proc/mdstat
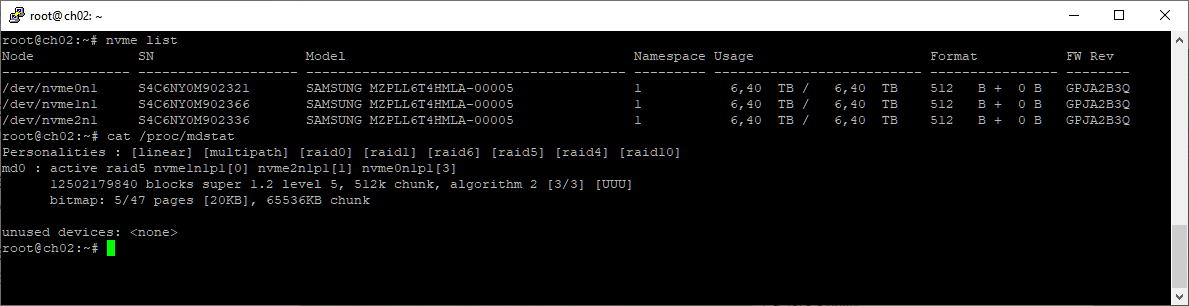
Имеем массив /dev/md0. Три диска по 6.4 ТБ в массиве RAID5 дают в общей сложности примерно 12 ТБ места, после утряски и усушки. Там крутится какая-то база данных, и места стало не хватать. Есть две проблемы:
- Переносить данные некуда, расширять массив требуется без удаления данных, допускается только кратковременная перезагрузка, простой больше 20 минут невозможен.
- На сервере только три слота PCIe, дополнительные диски воткнуть нельзя.
Было принято решение: заменить по очереди все три диска на Samsung SSD MZPLJ12THALA-00007 — NVMe 12.8 ТБ. После этого расширить массив и получить двукратный прирост массива до 24 ТБ.
Замена первого диска
Проверим что массив работает нормально.
mdadm --detail /dev/md0
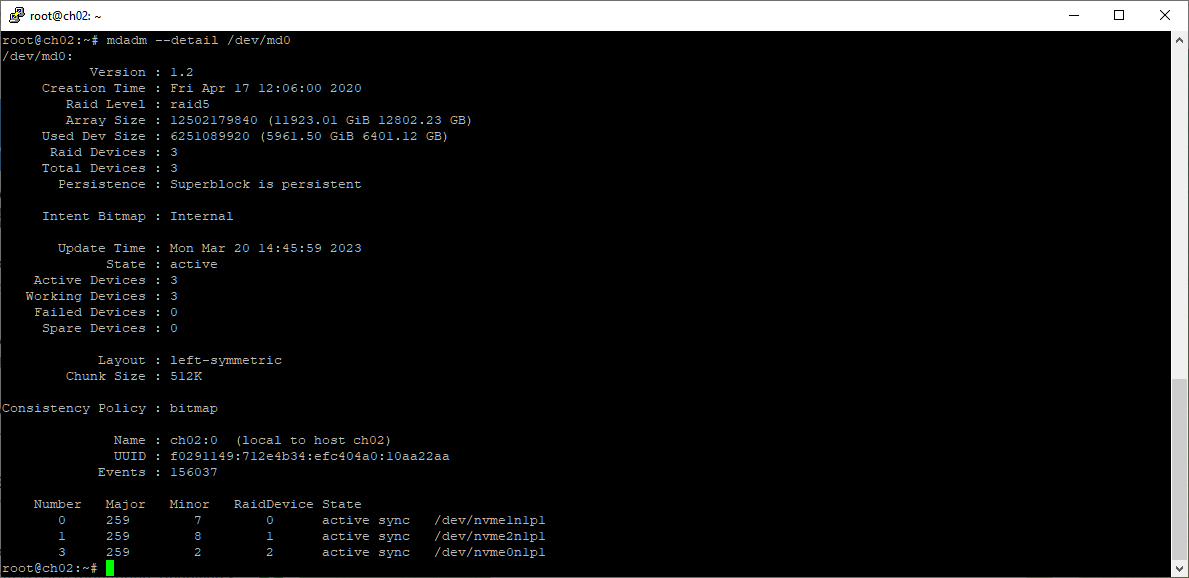
Массив в статусе active, все диски работают. Первым будем менять диск /dev/nvme0n1, переписываем его серийный номер (nvme list). Теперь нам нужно убрать из массива раздел /dev/nvme0n1p1, помечаем его как сбойный.
mdadm /dev/md0 --fail /dev/nvme0n1p1

Диск (раздел) переходит в состояние faulty, массив clean, degraded. Операции производятся, база работает. Пока всё прозрачно для пользователей.
Удаляем раздел из массива:
mdadm /dev/md0 --remove /dev/nvme0n1p1
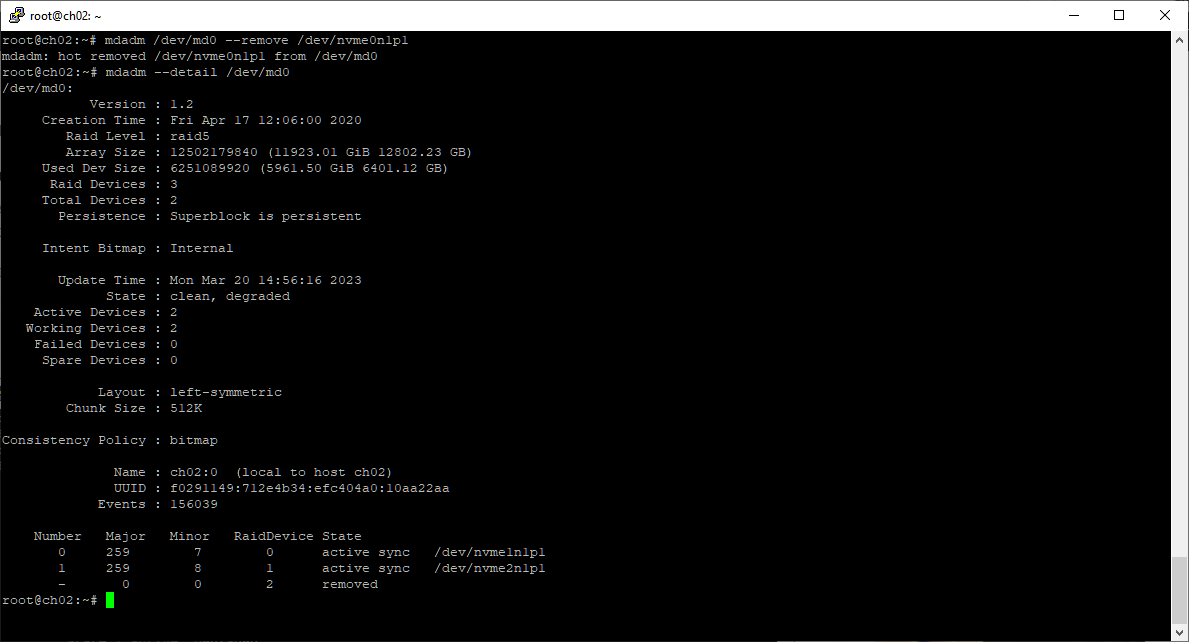
Правила хорошего тона — почистим за собой. Диск рабочий, потом будет использоваться где-нибудь.
wipefs --all --force /dev/nvme0n1
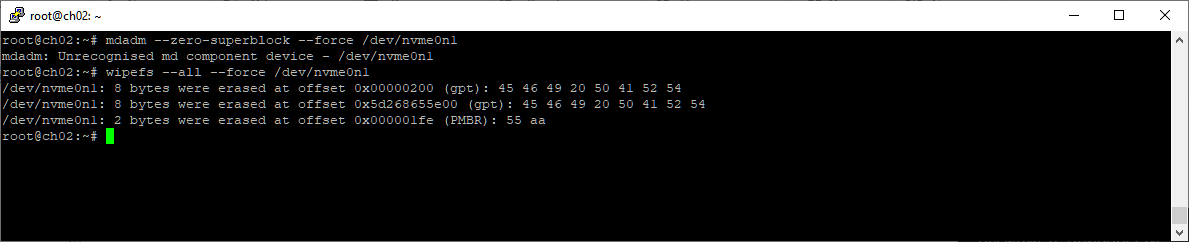
Если диск пойдёт на продажу, то лучше ещё и занулить всё.
cat /proc/mdstat
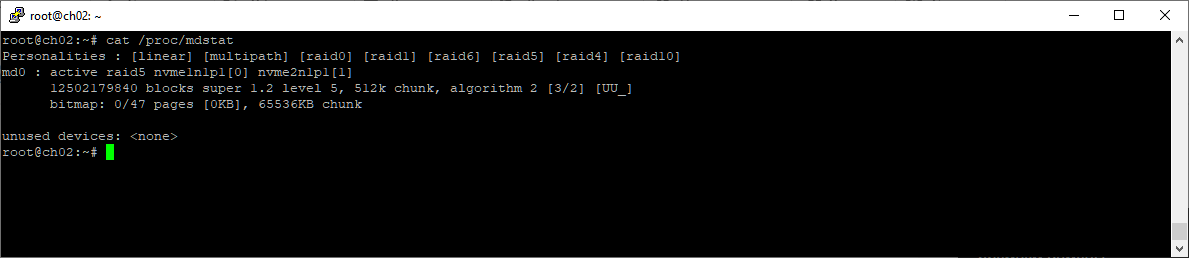
Массив в данный момент работает на двух дисках.
Сервер HPE Proliant DL360 Gen9 имеет только три слота PCIe, и все они заняты дисками. Два диска с низкопрофильной планкой, один диск — с полнопрофильной. Не знаю в каком слоте установлен первый диск, беру с собой диск с обоими планками.

У нас есть 20 минут на замену диска. Выключаем сервер, выдвигаем из стойки, снимаем крышку.

Диски в PCIe слотах установлены таким образом, что этикетку видно только у одного, и то не полностью.

Большой райзер с двумя дисками легко извлекается. Оба серийных номера не те.

Получается, нужный нам первый диск в третьем слоте. Приподнимаем синюю защёлку, нам нужно добраться до фиксирующего винта.

Для ускорения процесса я просто снимаю защёлку.

Откручиваем винт, понадобится торкс. Откручиваем не до конца, откидываем скобу.

Извлекаем диск. Сверяем серийный номер, это именно тот диск, который мы удалили из массива.

Для установки нового диска нам понадобится короткая планка.

Устанавливаем на новый диск короткую планку.

Устанавливаем новый диск на 12 ТБ в третий слот.

Возвращаем райзер с двумя старыми дисками на место.

Собираем всё обратно и включаем сервер. На работы ушло минут 10, ещё загружаться будет минут пять.
Сервер загрузился, работает. Дальше можно не торопиться.
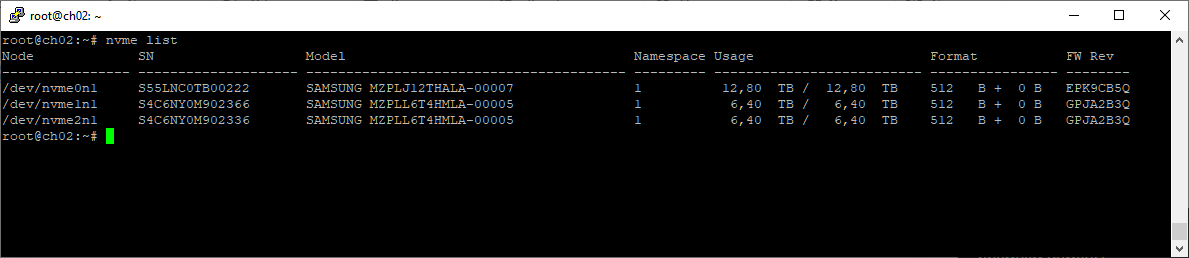
Диск определился, /dev/nvme0n1 теперь на 12 ТБ. Нумерация дисков не изменилась. Еду домой, дальше удобнее работать с домашнего компьютера по удалёнке.
Перед тем как добавить диск в массив, создам на нём раздел. Можно и сам диск добавлять, но я предпочитаю добавлять разделы. Раздел GPT создаю с помощью fdisk.
fdisk /dev/nvme0n1
g
n
w

Список разделов можно посмотреть командой:
lsblk | grep nvme

Добавлять в массив будем раздел /dev/nvme0n1p1.
mdadm /dev/md0 --add /dev/nvme0n1p1
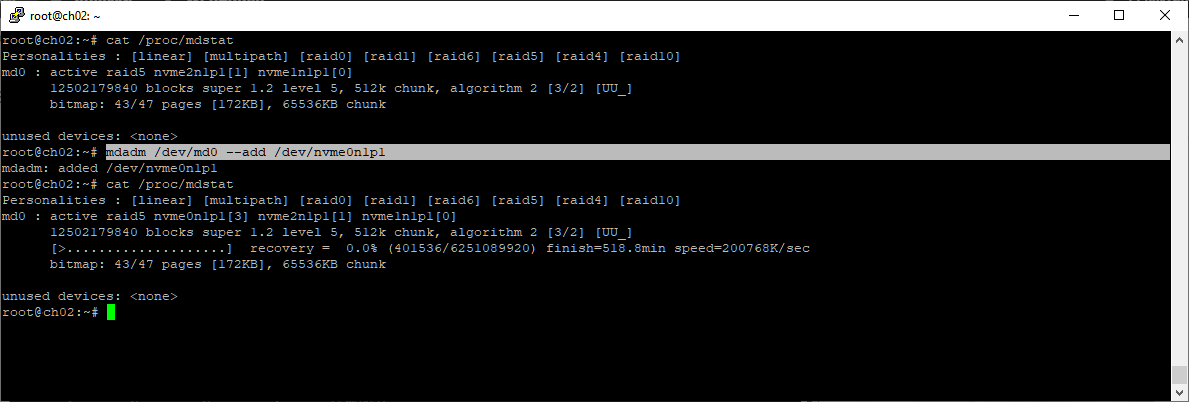
Раздел добавился в массив. Поскольку объём диска не меньше предыдущего, то началось восстановление массива. Массив в статусе recovery. После восстановления диск будет использован только наполовину. Оставляю восстанавливаться.
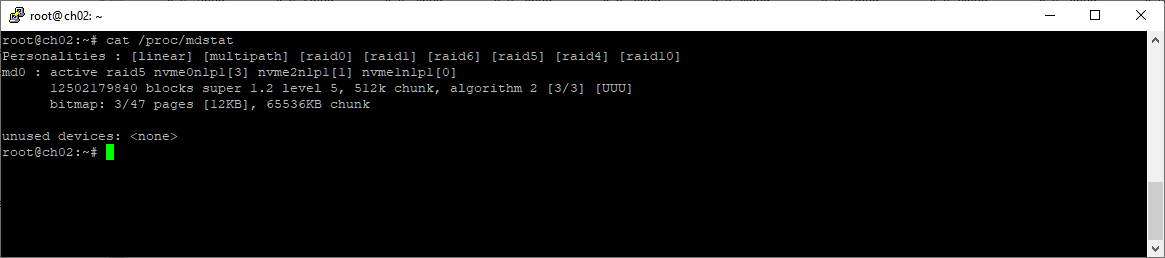
Массив восстановлен, первый этап завершён.
Замена второго диска
Покой нам только снится, выбираем второй диск для замены.
nvme list
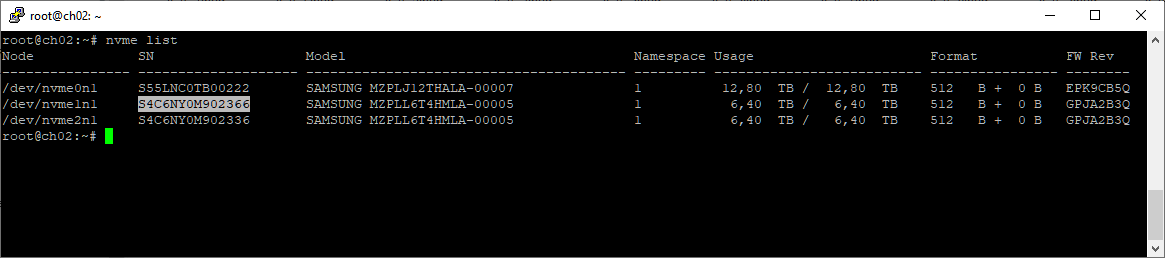
Вторым будем менять /dev/nvme1n1. Переписываю серийный номер.
Помечаем раздел /dev/nvme1n1p1 как сбойный и удаляем из массива:
mdadm /dev/md0 --fail /dev/nvme1n1p1
mdadm /dev/md0 --remove /dev/nvme1n1p1
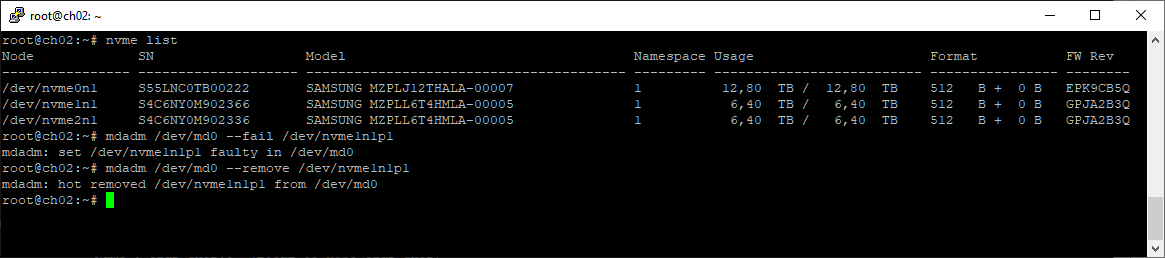
Чистим удаляемый диск:
wipefs --all --force /dev/nvme1n1

Массив работает, но на двух дисках.
cat /proc/mdstat

Статус: clean, degraded.
mdadm --detail /dev/md0
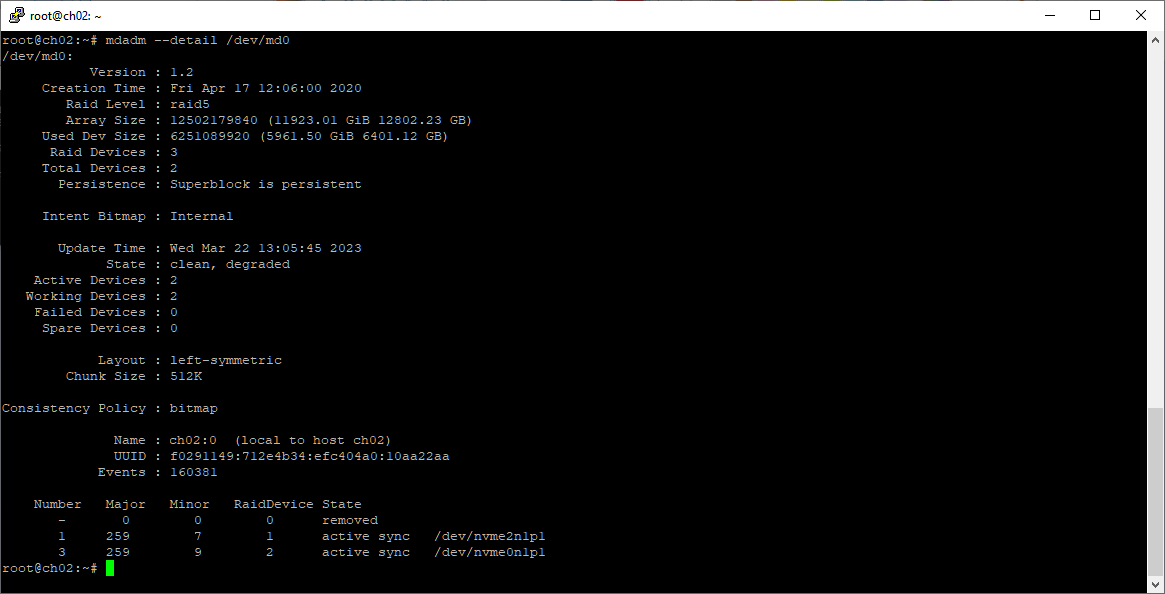
Беру второй диск, планки. Еду в ЦОД.
Выключаю сервер, извлекаю райзер с двумя дисками. На этот раз процесс идёт быстрее.

По серийному номеру определяю, что менять нужно диск в первом слоте.

Меняю диск.

Устанавливаю в сервер. Закрываю крышкой, включаю. Сервер заработал, массив определился. На всё ушло 10 минут. Теперь можно не торопиться.
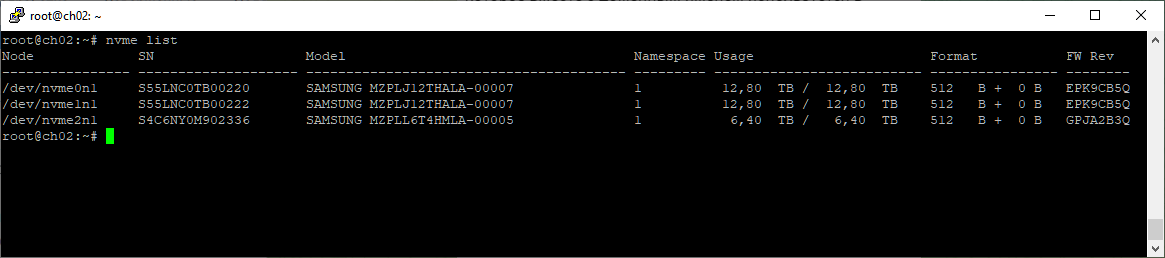
Теперь у нас два диска объёмом 12 ТБ. Казалось бы что всё в порядке, но не совсем, есть один важный момент:
cat /proc/mdstat
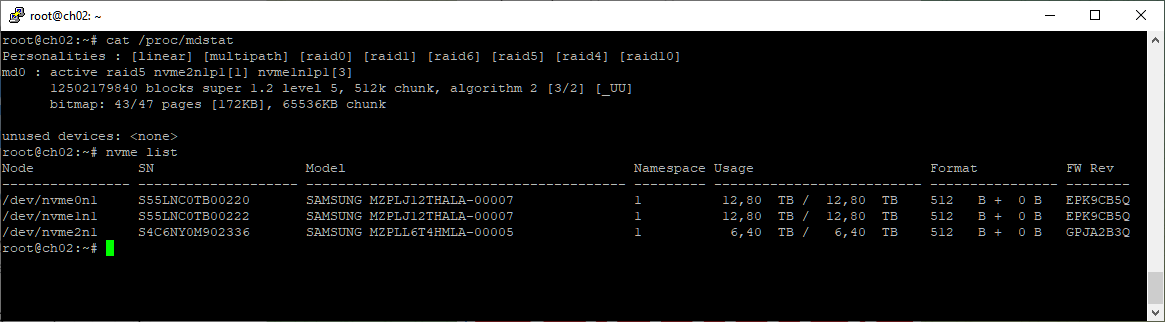
Смотрим внимательно и видим, что в массиве у нас сейчас два раздела:
- nvme2n1p1
- nvme1n1p1
У нас изменилась нумерация дисков и их названия! Наш второй установленный диск вовсе не /dev/nvme1n1, а /dev/nvme0n1. То же самое можно определить по серийному номеру, вероятно, ОС сортирует диски по серийным номерам, а не по слотам PCIe.
Список разделов тоже нам покажет диск, у которого ещё нет GPT раздела:
lsblk | grep nvme

Раздел GPT создаю с помощью fdisk:
fdisk /dev/nvme0n1
g
n
w
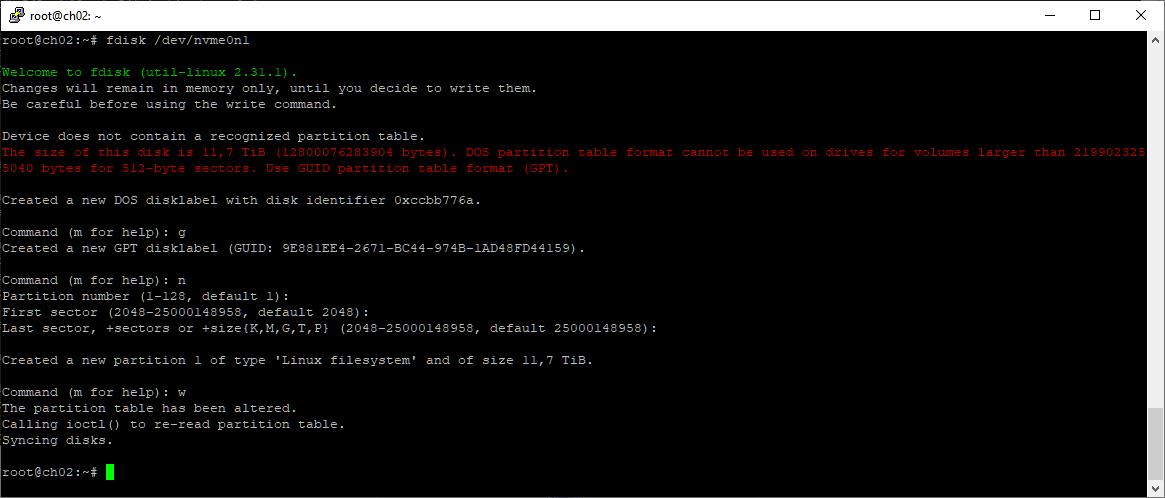
Проверяем что раздел создан с помощью lsblk:
lsblk | grep nvme

Добавляем в массив раздел /dev/nvme0n1p1.
mdadm /dev/md0 --add /dev/nvme0n1p1
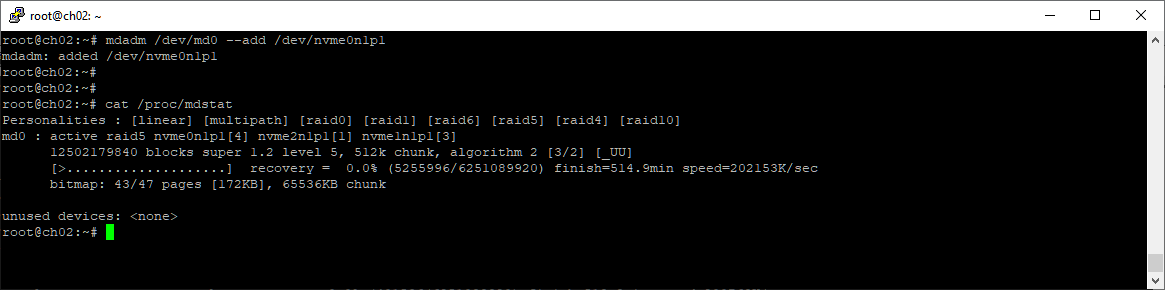
Раздел добавился в массив, началось восстановление массива. Массив в статусе recovery.
mdadm --detail /dev/md0
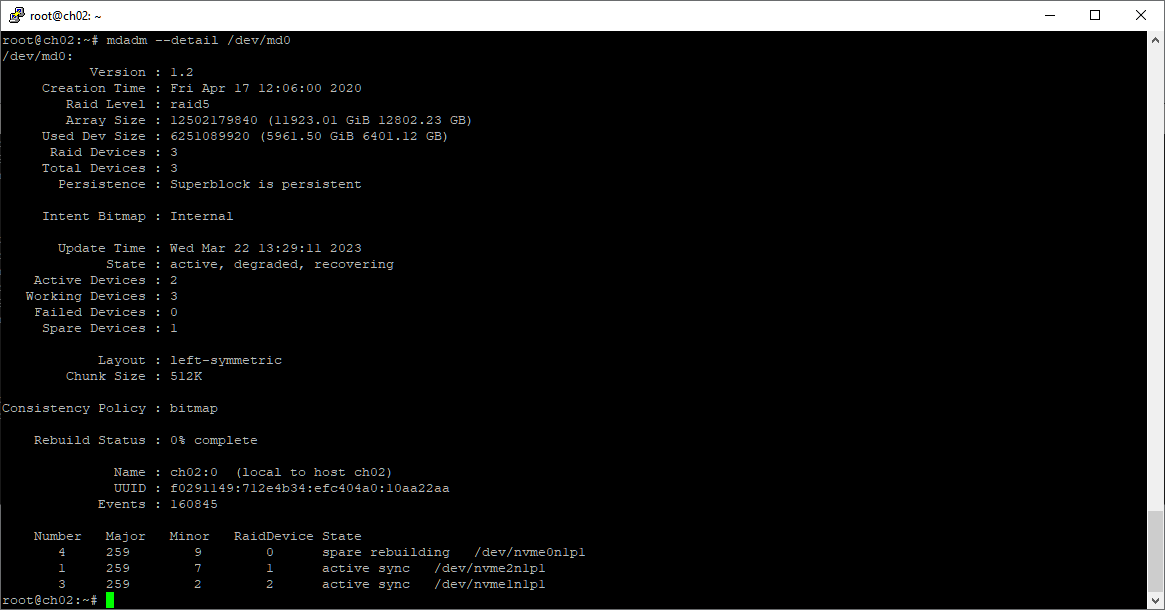
Сейчас статус массива active, degraded, recovering. Оставляю сервер работать, занимаюсь другими делами.
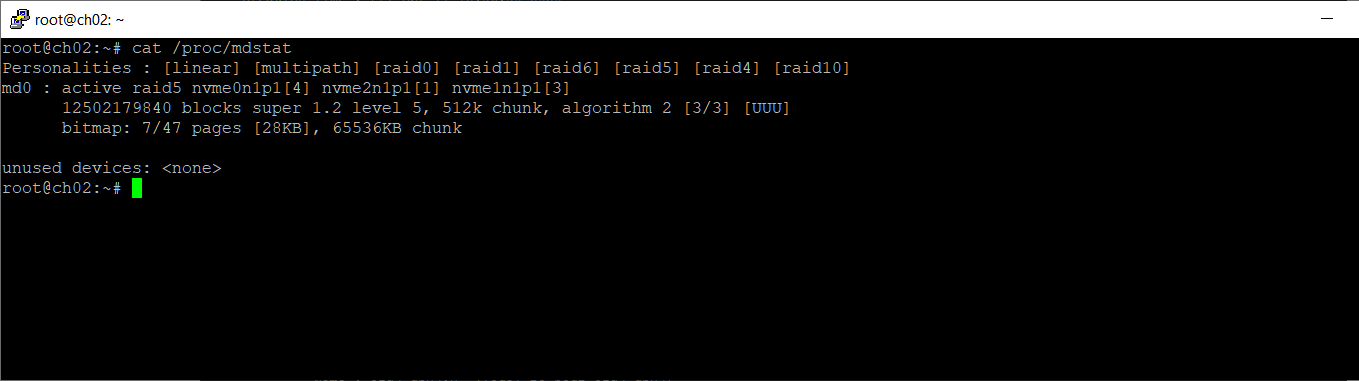
На следующий день массив восстановился.
Замена третьего диска
Третий раз закинул он невод, выбираем второй диск для замены. Выбирать не очень сложно, потому как 6 ТБ диск остался только один.
nvme list

Третьим будем менять /dev/nvme2n1. Переписываю серийный номер.
Помечаем раздел /dev/nvme2n1p1 как сбойный и удаляем из массива, чистим:
mdadm /dev/md0 --fail /dev/nvme2n1p1
mdadm /dev/md0 --remove /dev/nvme2n1p1
wipefs --all --force /dev/nvme2n1

Массив работает, но на двух дисках.
cat /proc/mdstat

Статус: clean, degraded.
mdadm --detail /dev/md0
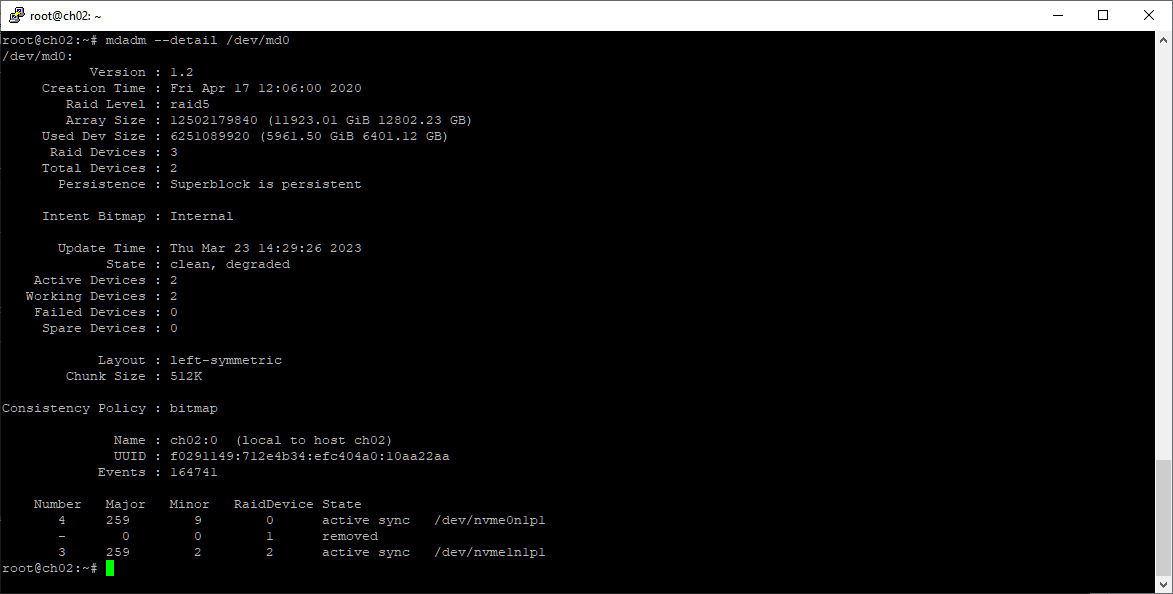
Беру третий диск. Сразу устанавливаю на него короткую планку. Еду в ЦОД.
Выключаю сервер, извлекаю райзер с двумя дисками.

Диск определять не нужно, он один такой на 6 ТБ, менять нужно диск во втором слоте.

Меняю диск.

Устанавливаю в сервер.

Закрываю крышкой, включаю. Сервер заработал, массив определился. На всё ушло 5 минут. Теперь можно не торопиться.

Теперь у нас все три диска объёмом 12 ТБ. И снова нумерация дисков изменилась, как видим, теория о сортировке по серийному номеру не подтвердилась, ну да ладно:
cat /proc/mdstat

Видим, что в массиве у нас сейчас два раздела:
- nvme2n1p1
- nvme0n1p1
Наш третий установленный диск /dev/nvme1n1.
lsblk | grep nvme

Раздел GPT создаю с помощью fdisk:
fdisk /dev/nvme1n1
g
n
w
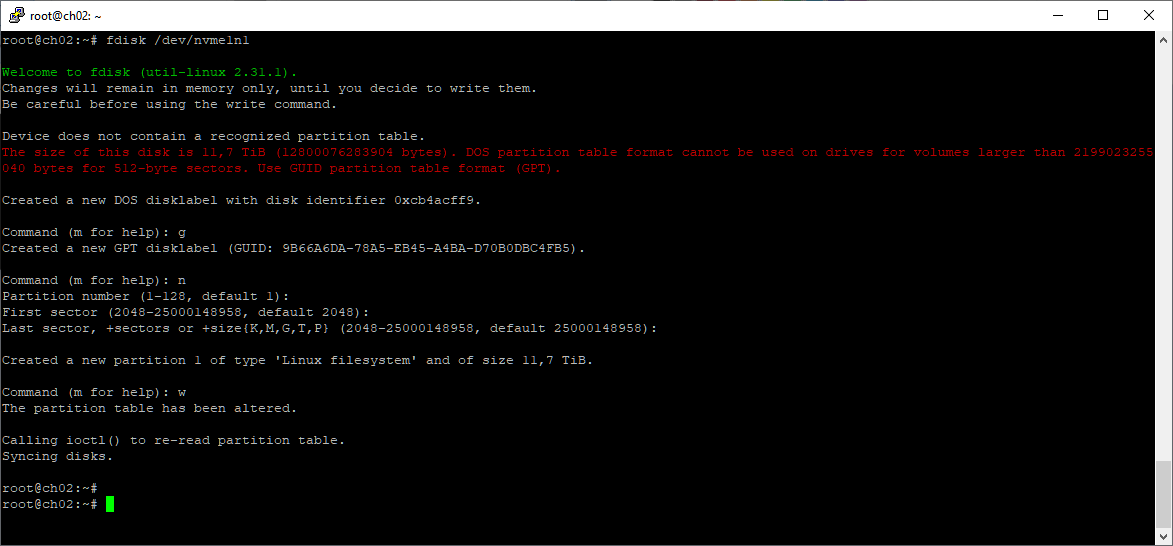
lsblk | grep nvme

Добавляем в массив раздел /dev/nvme1n1p1.
mdadm /dev/md0 --add /dev/nvme1n1p1
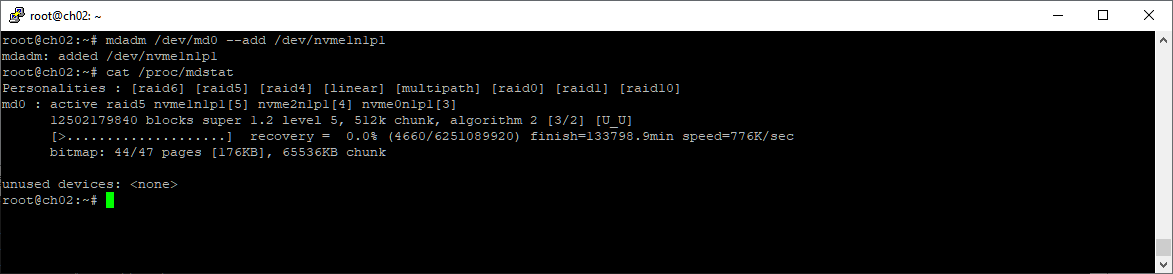
Раздел добавился в массив, началось восстановление массива. Массив в статусе recovery.
mdadm --detail /dev/md0
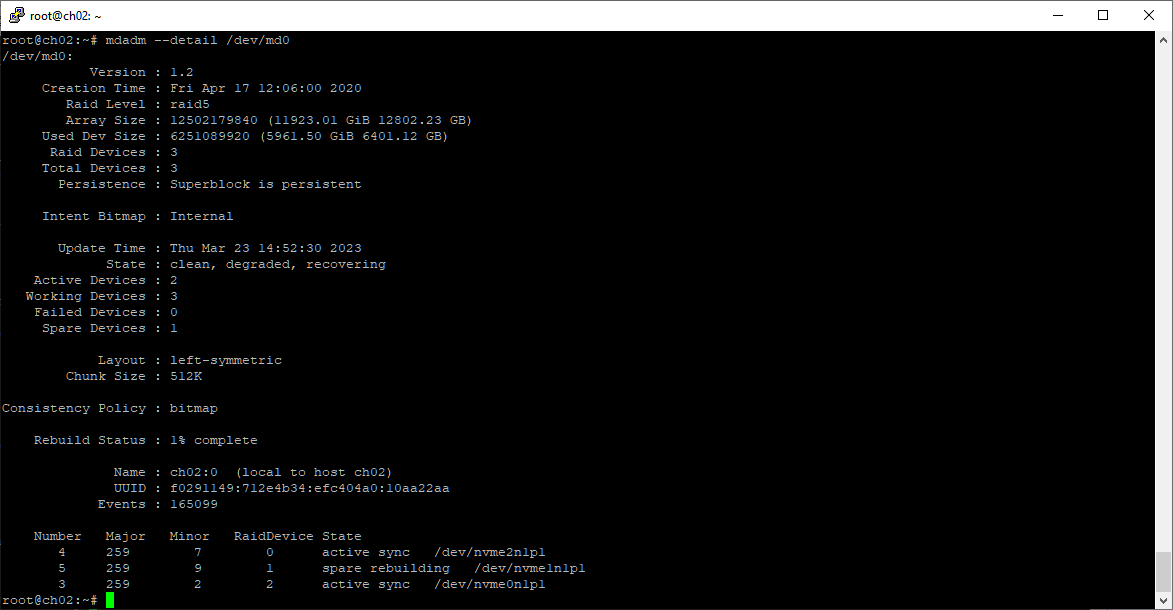
Сейчас статус массива clean, degraded, recovering. Оставляю сервер работать.
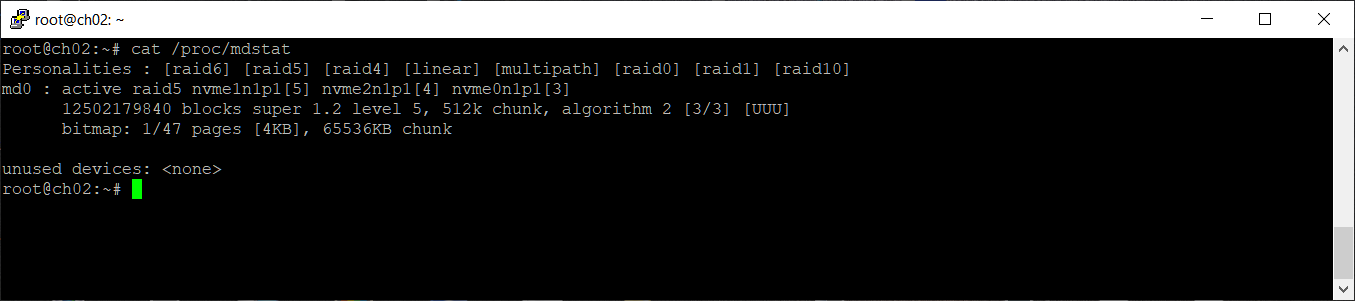
На следующий день массив восстановился.
Расширение массива
Теперь у нас есть RAID5 массив из трёх дисков по 12 ТБ, но размер у массива всё ещё прежний.
mdadm --detail /dev/md0
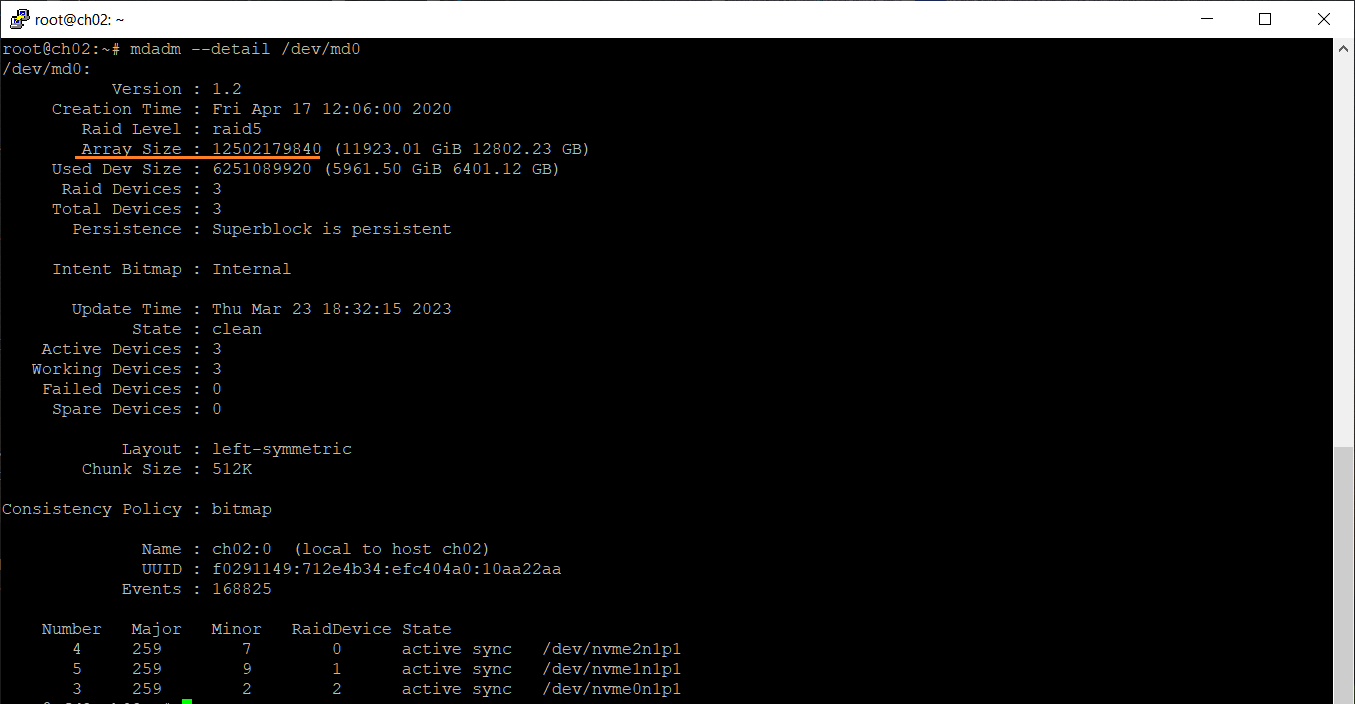
Array Size показывает, что объём массива 12 ТБ.
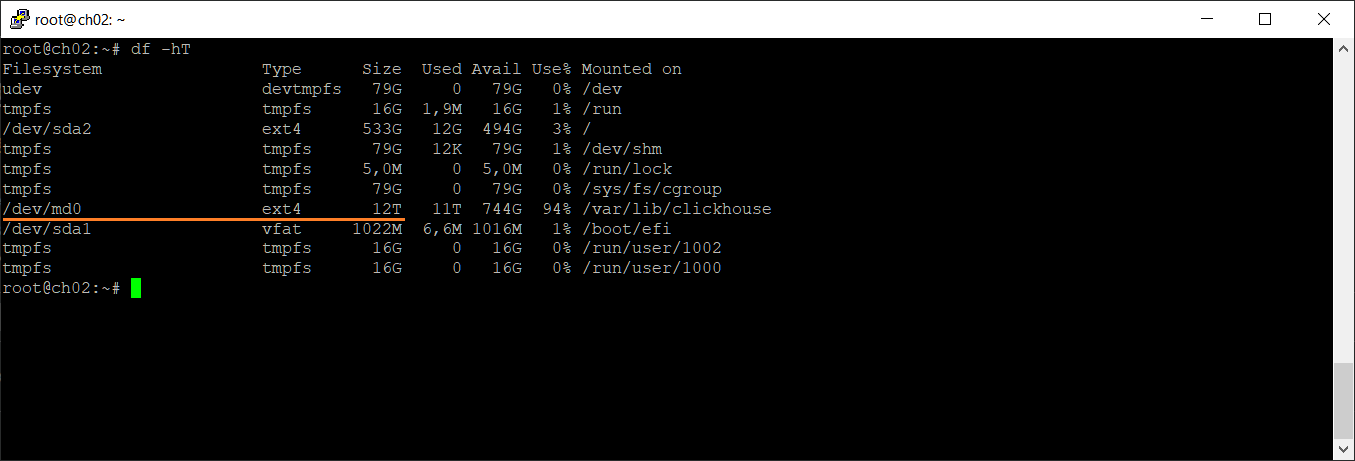
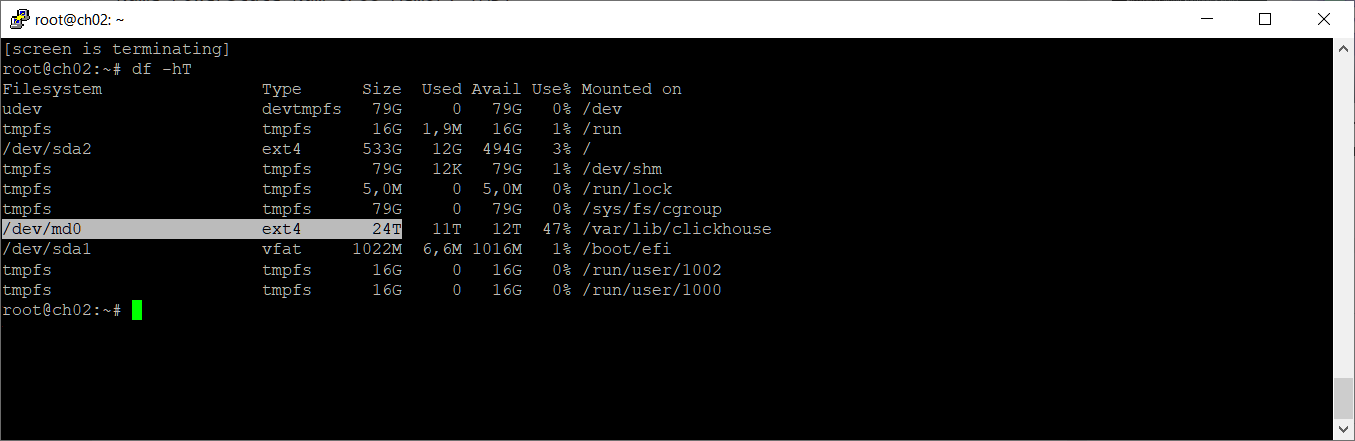
Размер смонтированной папки у нас как был 12 ТБ, так и остался.
Расширяем массив:
mdadm --grow /dev/md0 --size=max

Размер компонентов (думаю, что это Used Dev Size) увеличен.
mdadm --detail /dev/md0
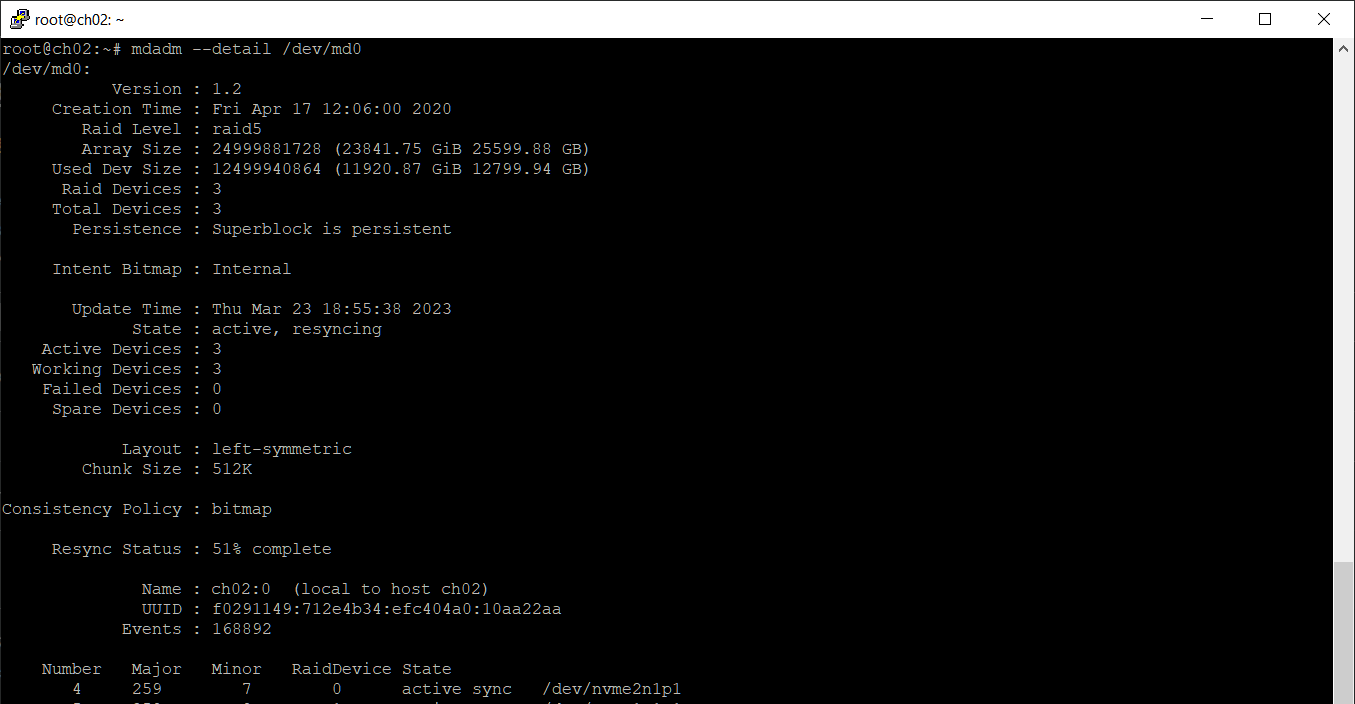
Действительно, Used Dev Size теперь 12 ТБ, а Array Size показывает, что объём массива 24 ТБ.
Массив в статусе active, resyncing. Дожидаемся окончания ресинхронизации, это небыстрый процесс.
После окончания синхронизации осталось увеличить размер файловой системы. У меня ext4, воспользуюсь resize2fs:
resize2fs /dev/md0
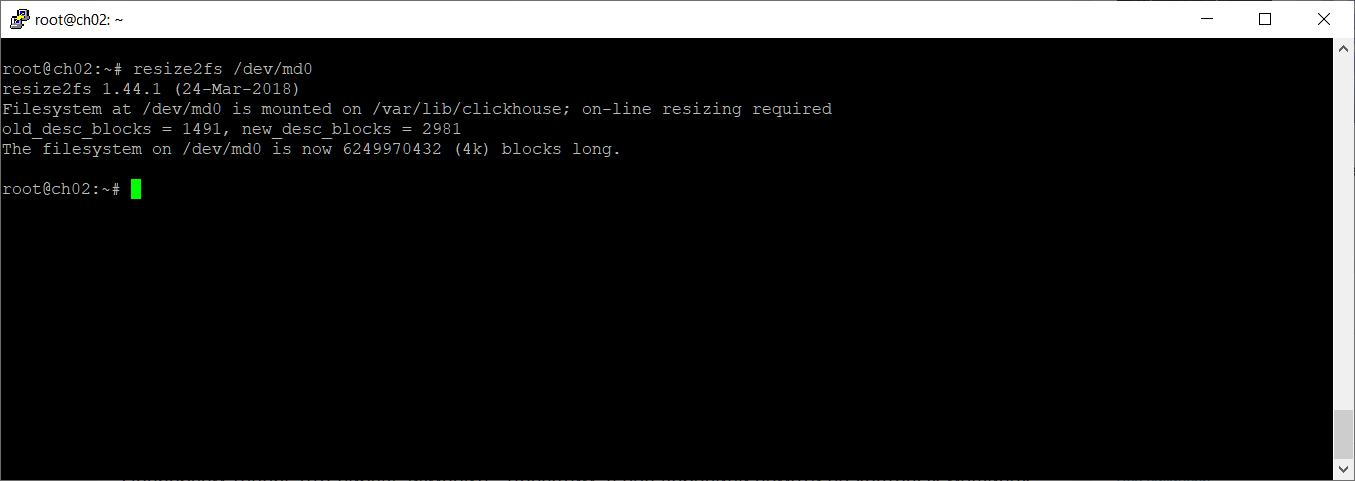
Размер папки увеличился до 24 ТБ.
Заключение
Работы по расширению RAID5 массиве из трёх дисков заняли 4 дня. Понадобилось три отключения сервера каждый раз на 20 минут для замены дисков. Всё остальное время сервер работал, и база данных на данном массиве тоже работала. Расширение массива было выполнено без копирования или переноса данных на лету. Потерь данных не допущено.
Естественно, в моменты перестроения массива имелся риск потери данных в случае выхода из строя любого диска. Поэтому, у нас имелся второй резервный сервер с теми же данными для подстраховки.
Прошло 4 месяца, массив работает.




















