Напоминалка. Если нам нужно удалить из файла дубликаты строк, то нельзя использовать операторы перенаправления ">" или ">>". Такие операторы имеют более высокий приоритет и начинают писать в файл ещё до того, как полностью считали из него же все строки.
Ну, как нельзя, можно, если использовать промежуточный файл, но это некрасиво.
На помощь приходят инструменты: tee, sponge (из пакета moreutils), sed -i, awk и другие инструменты записи в файл.
Сортировка и поиск дубликатов
Давайте сначала разберём пару способов поиска дубликатов строк.
Если у нас строки в файле уже отсортированы, то вычистить дубликаты можно командой uniq. Имеем файл test.txt:
Ася Боря Коля Коля Олег
Выполняем:
cat test.txt | uniq
или
uniq test.txt
Результат:
Ася Боря Коля Олег
Если у нас строки в файле не отсортированы, то нужно сортировать, например с sort. Имеем файл test.txt:
Ася Коля Боря Олег Коля
Выполняем:
cat test.txt | sort | uniq
или
sort test.txt | uniq
или
sort -u test.txt
Результат:
Ася Боря Коля Олег
С сортировкой и вычищением дубликатов разобрались.
Запись результата в тот же файл
А теперь самое интересное. Нам нужно сохранить результат в тот же самый файл. Операторы перенаправления можно использовать в данном случае только с промежуточным файлом, например:
sort -u test.txt > test.tmp
mv -f test.tmp test.txt
или одной строкой
sort -u test.txt > test.tmp; mv -f test.tmp test.txt
Можно использовать губку sponge, которая накапливает весь вывод перед вводом:
apt-get install moreutils
sort -u test.txt | sponge test.txt
Можно использовать тройник tee:
sort -u test.txt | tee test.txt
или без вывода на экран
sort -u test.txt | tee test.txt >/dev/null
И самый, на мой взгляд, оптимальный метод вывода в файл без перенаправления:
sort -u test.txt -o test.txt
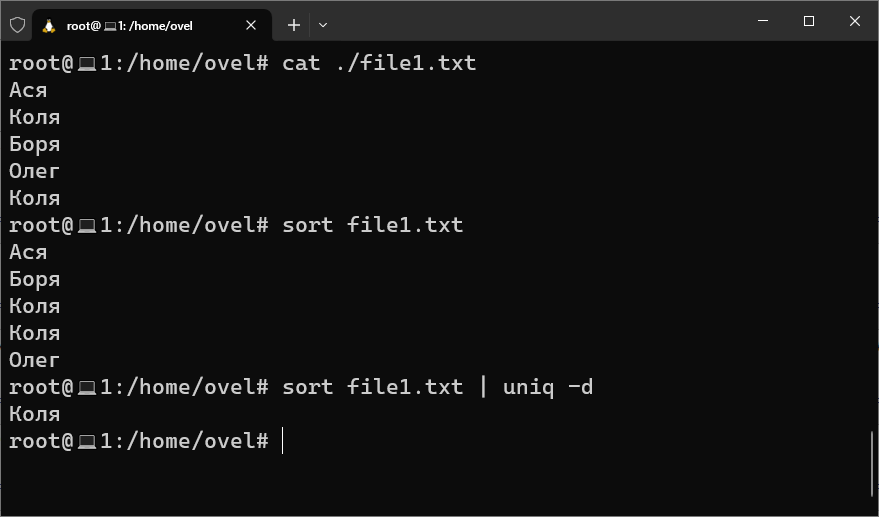
Вывод дубликатов
Если задача состоит в том, чтобы вывести на экран из файла только те строки, которые имеют дубли, то сначала сортируем строки с помощью sort, потом отображаем только неуникальные значения с помощью uniq с атрибутом -d:
sort file1.txt | uniq -d